 |
The AHA Model
Revision: 17463
Reference implementation 04 (HEDG02_04)
|
|
The AHA Model
Revision: 17463
Reference implementation 04 (HEDG02_04)
|
Define the population of agents object, its properties and functions. More...
Data Types | |
| type | member_population |
| Definition of individual member of a population. More... | |
| type | population |
| Definition of the population object. More... | |
Functions/Subroutines | |
| subroutine | set_individual_id (this, idnumber) |
| Set integer ID number to individual member of the population object. More... | |
| integer function | get_individual_id (this) |
| Get integer ID number to individual member of the population object. More... | |
| subroutine | individ_posit_in_environ_uniform (this, environ) |
| Places the individual agent, a member of the population, within a specific environment at random with a uniform distribution. The agents can be positioned with respect to their initial depth. More... | |
| subroutine | genome_individual_set_dead_non_pure (this, non_debug_log) |
| Set the individual to be dead. Note that this function does not deallocate the individual agent object, this may be a separate destructor function. More... | |
| subroutine | init_population_random (this, pop_size, pop_number_here, pop_name_here) |
| Initialise the population object. More... | |
| subroutine | population_destroy_deallocate_objects (this) |
| Destroys this population and deallocates the array of individual member objects. More... | |
| subroutine | population_birth_mortality_init (this, energy_mean, energy_sd) |
| Impose selective mortality at birth on the agents. Selective mortality sets a fixed limit on uncontrolled evolution of the energy reserves in newborn agents. If some newborn has too high energy at birth (genetically fixed), such a deviating agent is killed at once. More... | |
| integer function | population_get_popsize (this) |
| Accessor get-function for the size of this population. More... | |
| integer function | population_get_pop_number (this) |
| Accessor get-function for the population number ID. More... | |
| character(len=label_length) function | population_get_pop_name (this) |
| Accessor get-function for the population character label ID. More... | |
| subroutine | reset_population_id_random (this, pop_number_here, pop_name_here) |
| Reset individual IDs of the population members. More... | |
| subroutine | sex_initialise_from_genome (this) |
| Determine the sex for each member of the population. More... | |
| subroutine | position_individuals_uniform (this, environ) |
| Position each member of the population randomly within a bounding environment. More... | |
| elemental subroutine | sort_population_by_fitness (this) |
This subroutine sorts the population individual object by their %fitness components. More... | |
| subroutine | population_rwalk3d_all_agents_step (this, dist_array, cv_array, dist_all, cv_all, environment_limits, n_walks) |
| Perform one or several steps of random walk by all agents. More... | |
| subroutine | population_rwalk25d_all_agents_step (this, dist_array_xy, cv_array_xy, dist_array_depth, cv_array_depth, dist_all_xy, cv_all_xy, dist_all_depth, cv_all_depth, environment_limits, n_walks) |
| Perform one or several steps of random walk by all agents. More... | |
| subroutine | population_subject_predator_attack (this, this_predator, time_step_model) |
| Subject the population to an attack by a specific predator. The predator acts on agents in its proximity and takes account of the predation confusion and dilution effects (see the_environment::predator::risk_fish_group()). More... | |
| subroutine | population_subject_other_risks (this) |
| Subject the population to mortality caused by habitat-specific mortality risk. Each agent is affected by the risk associated with the habitat it is currently in. More... | |
| subroutine | population_subject_individual_risk_mortality (this) |
| Subject all members of this population to their individual mortality risks. More... | |
| subroutine | population_lifecycle_step_preevol (this) |
| This procedure performs a single step of the life cycle of the whole population, the agents for the step are selected in a random order. More... | |
| subroutine | population_lifecycle_step_eatonly_preevol (this) |
| This procedure performs a single step of the life cycle of the whole population, the agents for the step are selected in a random order. More... | |
| subroutine | population_save_data_all_agents_csv (this, csv_file_name, save_header, is_logging, is_success) |
| Save data for all agents within the population into a CSV file. More... | |
| subroutine | population_save_data_all_genomes (this, csv_file_name, is_success) |
| Save the genome data of all agents in this population to a CSV file. More... | |
| subroutine | population_load_data_all_genomes (this, pop_size, pop_number_here, pop_name_here, csv_file_name, missing_random, is_success) |
| Load the genome data of all agents in this population from a CSV file. Note that the procedure implements several error correcting measures, e.g. checks for minimum number of rows in the file and minimum row length. The input CSV file therefore can include short text notes that are then ignored when reading data. More... | |
| subroutine | population_save_data_memory (this, csv_file_name, is_success) |
| Save the perceptual and emotional memory stack data of all agents in this population to a CSV file. More... | |
| subroutine | population_save_data_movements (this, csv_file_name, is_success) |
| Save the latest movement history of all agents. This method makes use of the the_environment::spatial_moving::history structure that saves latest movements of each agent. More... | |
| subroutine | population_save_data_behaviours (this, csv_file_name, is_success) |
| Save the behaviours history stack the_neurobio::behaviour::history_behave for all agents. More... | |
| pure subroutine | population_preevol_fitness_calc (this) |
| Calculate fitness for the pre-evolution phase of the genetic algorithm. Pre-evolution is based on selection for a simple criterion without explicit reproduction etc. The criterion for selection at this phase is set by the integer the_individual::individual_agent::fitness component. This procedure provides a whole-population wrapper for the the_individual::individual_agent::fitness_calc() function. More... | |
| pure integer function | population_ga_reproduce_max (this) |
| Determine the number of parents that have fitness higher than the minimum acceptable value. Also, only alive agents are included into the reproducing number. More... | |
| real(srp) function | population_ga_mutation_rate_adaptive (this, baseline, maxvalue) |
| This function implements adaptive mutation rate that increases as the population size reduces. More... | |
Variables | |
| character(len= *), parameter, private | modname = "(THE_POPULATION)" |
| integer, public | global_ind_n_eaten_by_predators |
| Global indicator variable that keeps the number of agents that have died as a consequence of predatory attacks. All other dies are therefore caused by starvation. More... | |
Define the population of agents object, its properties and functions.
The population is in the simplest case an array of individual agent objects. Individual properties of the population members can be referred as, e.g. proto_parentsindividual(i)fitness .
| subroutine the_population::set_individual_id | ( | class(member_population), intent(inout) | this, |
| integer, intent(in) | idnumber | ||
| ) |
Set integer ID number to individual member of the population object.
| [in,out] | this | class, member of population. |
| [in] | idnumber | id, integer id number assigned. |
person_number is assigned the idnumber
Definition at line 191 of file m_popul.f90.
| integer function the_population::get_individual_id | ( | class(member_population), intent(in) | this | ) |
Get integer ID number to individual member of the population object.
| [in] | this | class, member of population. |
| id,integer | id number retreived. |
person_number is assigned the idnumber
Definition at line 205 of file m_popul.f90.
| subroutine the_population::individ_posit_in_environ_uniform | ( | class(member_population), intent(inout) | this, |
| class(environment), intent(in) | environ | ||
| ) |
Places the individual agent, a member of the population, within a specific environment at random with a uniform distribution. The agents can be positioned with respect to their initial depth.
| [in] | environ | environ sets the environment object where the agent is placed randomly |
Definition at line 223 of file m_popul.f90.
| subroutine the_population::genome_individual_set_dead_non_pure | ( | class(member_population), intent(inout) | this, |
| logical, intent(in), optional | non_debug_log | ||
| ) |
Set the individual to be dead. Note that this function does not deallocate the individual agent object, this may be a separate destructor function.
dies procedure from the_genome and all its overrides:
dies from ÌNDIVIDUAL_GENOME. Local flag to do show log.
Local parameter showing how many latest memory values to log out.
Don't show log by default.
This is a pure function from THE_GENOME level.
Turn on output logging only if in the DEBUG mode or if non_debug_log is explicitly set to TRUE.
Just exit back if no logging.
TOSTR accepts arrays including (concatenated) character arrays.Definition at line 261 of file m_popul.f90.
| subroutine the_population::init_population_random | ( | class(population), intent(inout) | this, |
| integer, intent(in) | pop_size, | ||
| integer, intent(in), optional | pop_number_here, | ||
| character (len=*), intent(in), optional | pop_name_here | ||
| ) |
Initialise the population object.
Initialise the population object, init it with random individuals (function init on individuals), and assign sequential person_number`s.
| [in,out] | this | class, This – member of population class (this)). |
| [in] | pop_size | pop_size, The size of the population. |
| [in] | pop_number_here | id, Optional numeric population ID. |
| [in] | pop_name_here | descriptor, Optional population string descriptor. |
Set population size from input parameter.
Allocate the population
Initialise all individuals of the population
first, call `init to object individual(i)
Set optional descriptors for the whole population. Numeric ID and a short text description.
If optional ID is absent, ID is set to a random integer value from 1 to the maximum integer allowed for the pop_number type (minus 1).
If optional text description string of the population is absent, it is set to the string representation of its numeric ID.
Log the initial location of the agents.
Definition at line 318 of file m_popul.f90.
| subroutine the_population::population_destroy_deallocate_objects | ( | class(population), intent(inout) | this | ) |
Destroys this population and deallocates the array of individual member objects.
Definition at line 391 of file m_popul.f90.
| subroutine the_population::population_birth_mortality_init | ( | class(population), intent(inout) | this, |
| real(srp), intent(in), optional | energy_mean, | ||
| real(srp), intent(in), optional | energy_sd | ||
| ) |
Impose selective mortality at birth on the agents. Selective mortality sets a fixed limit on uncontrolled evolution of the energy reserves in newborn agents. If some newborn has too high energy at birth (genetically fixed), such a deviating agent is killed at once.
The values of the risk are chosen such that it is zero at the fixed population mean (agent does not deviate) and reaches 1.0 if the agent's energy reserves are 3.0 standard deviations higher than the fixed mean value (agent strongly deviates).
| [in] | energy_mean | energy_mean optional mean energy at birth, if absent, is calculated from the population data. |
| [in] | energy_sd | energy_sd optional mean energy at birth, if absent, is calculated from the population data. |
MORTALITY_BIRTH_INIT_ENERG_ABSCISSA is the baseline abscissa for the nonparametric interpolation function grid, in units of the standard deviation (sigma) of the energy reserves in the newborn population, i.e. the_body::condition::energy_birth.MORTALITY_BIRTH_INIT_ENERG_ORDINATE is the ordinate for the nonparametric interpolation function grid: sets the probability of the agent's death given its energy reserves deviate from the fixed mean by the number of standard deviations set by MORTALITY_BIRTH_INIT_ENERG_ABSCISSA.Selective mortality sets a fixed limit on uncontrolled evolution of the energy reserves in newborn agents. All newborn agents that have the energy reserves exceeding some point may die with the probability determined by the grid arrays:
MORTALITY_BIRTH_INIT_ENERG_ABSCISSA;MORTALITY_BIRTH_INIT_ENERG_ORDINATE.The probability of death (mortality risk) is determined by the nonparametric nonlinear function defined by DDPINTERPOL, where the actual grid abscissa is the energy reserve of the agent in and grid ordinate is the mortality risk.
The values of the risk are chosen such that it is zero at the fixed population mean (agent does not deviate) and reaches 1.0 if the agent's energy reserves are 3.0 standard deviations higher than the mean value.
Interpolation plots can be saved in the debug mode using this plotting command: commondata::debug_interpolate_plot_save().
Definition at line 411 of file m_popul.f90.
| integer function the_population::population_get_popsize | ( | class(population), intent(in) | this | ) |
Accessor get-function for the size of this population.
Definition at line 510 of file m_popul.f90.
| integer function the_population::population_get_pop_number | ( | class(population), intent(in) | this | ) |
Accessor get-function for the population number ID.
Definition at line 520 of file m_popul.f90.
| character(len=label_length) function the_population::population_get_pop_name | ( | class(population), intent(in) | this | ) |
Accessor get-function for the population character label ID.
Definition at line 530 of file m_popul.f90.
| subroutine the_population::reset_population_id_random | ( | class(population), intent(inout) | this, |
| integer, intent(in), optional | pop_number_here, | ||
| character (len=*), intent(in), optional | pop_name_here | ||
| ) |
Reset individual IDs of the population members.
Makes new random individual IDs for the population members.
| [in,out] | this | class, This – member of population class (this)). |
| [in] | pop_number_here | id, Optional numeric population ID. |
| [in] | pop_name_here | descriptor, Optional population string descriptor. |
Reset all individual IDs of the population members
Set optional descriptors for the whole population. Numeric ID and a short text description.
If optional ID is absent, ID is set to a random integer value from 1 to the maximum integer allowed for the pop_number type (minus 1).
If optional text description string of the population is absent, it is set to the string representation of its numeric ID.
Definition at line 541 of file m_popul.f90.
| subroutine the_population::sex_initialise_from_genome | ( | class(population), intent(inout) | this | ) |
Determine the sex for each member of the population.
Definition at line 579 of file m_popul.f90.
| subroutine the_population::position_individuals_uniform | ( | class(population), intent(inout) | this, |
| class(environment), intent(in), optional | environ | ||
| ) |
Position each member of the population randomly within a bounding environment.
| [in] | environ | environ the environment where we place the population |
Local object representing the bounding environment for this population
Local counter
Check if the bounding environment is provided, if not, place agents without limits
Position agents randomly (uniform distribution) within the bounding environment.
Definition at line 596 of file m_popul.f90.
| elemental subroutine the_population::sort_population_by_fitness | ( | class(population), intent(inout) | this | ) |
This subroutine sorts the population individual object by their %fitness components.
The two subroutines qsort and qs_partition_fitness are a variant of the recursive quick sort algorithm adapted for MEMBER_POPULATION integer fitness component
| [in,out] | this | class, This – member of population class (this)). |
This is the array component we sort.
Definition at line 637 of file m_popul.f90.
| subroutine the_population::population_rwalk3d_all_agents_step | ( | class(population), intent(inout) | this, |
| real(srp), dimension(:), intent(in), optional | dist_array, | ||
| real(srp), dimension(:), intent(in), optional | cv_array, | ||
| real(srp), intent(in), optional | dist_all, | ||
| real(srp), intent(in), optional | cv_all, | ||
| class(environment), intent(in), optional | environment_limits, | ||
| integer, intent(in), optional | n_walks | ||
| ) |
Perform one or several steps of random walk by all agents.
| [in] | dist_array | step_size_array an array of step sizes for each individual. |
| [in] | cv_array | cv_array Coefficients of variation for the walk. |
| [in] | dist_all | dist_all the value of the walk step size that is identical in all agents within the population. |
| [in] | cv_all | cv_all the value of the walk coefficient of variation that is identical in all agents within the population. |
| [in] | environment_limits | environment_limits Limits of the environment area available for the random walk. The moving object cannot get beyond this limit. If this parameter is not provided, the environmental limits are obtained automatically from the global array the_environment::global_habitats_available. |
| [in] | n_walks | n_walk optional number of walk steps that should be performed, default just one. |
calculate the step size along the axes from the distance array.
pop_permutation array.Definition at line 725 of file m_popul.f90.
| subroutine the_population::population_rwalk25d_all_agents_step | ( | class(population), intent(inout) | this, |
| real(srp), dimension(:), intent(in), optional | dist_array_xy, | ||
| real(srp), dimension(:), intent(in), optional | cv_array_xy, | ||
| real(srp), dimension(:), intent(in), optional | dist_array_depth, | ||
| real(srp), dimension(:), intent(in), optional | cv_array_depth, | ||
| real(srp), intent(in), optional | dist_all_xy, | ||
| real(srp), intent(in), optional | cv_all_xy, | ||
| real(srp), intent(in), optional | dist_all_depth, | ||
| real(srp), intent(in), optional | cv_all_depth, | ||
| class(environment), intent(in), optional | environment_limits, | ||
| integer, intent(in), optional | n_walks | ||
| ) |
Perform one or several steps of random walk by all agents.
| [in] | dist_array_xy | dist_array_xy an array of step sizes for each individual. |
| [in] | cv_array_xy | cv_array_xy Coefficients of variation for the walk. |
| [in] | dist_array_depth | dist_array_depth an array of step sizes for each individual. |
| [in] | cv_array_depth | cv_array_depth Coefficients of variation for the walk. |
| [in] | dist_all_xy | dist_all_xy the value of the walk step size for horizontal plane that is identical in all agents within the population. |
| [in] | cv_all_xy | cv_all_xy the value of the walk coefficient of variation in the horizontal plane that is identical in all agents within the population. |
| [in] | dist_all_depth | dist_all_depth the value of the walk step size for the depth plane that is identical in all agents within the population. |
| [in] | cv_all_depth | cv_all_depth the value of the walk coefficient of variation in the depth plane that is identical in all agents within the population. |
| [in] | environment_limits | environment_limits Limits of the environment area available for the random walk. The moving object cannot get beyond this limit. If this parameter is not provided, the environmental limits are obtained automatically from the global array the_environment::global_habitats_available. |
| [in] | n_walks | n_walk optional number of walk steps that should be performed, default just one. |
If the depth walk step distance is not provided as a parameter, 1/2 of the agent body size is used as the default value. Thus, it is assumed that the extent of random movements of the agents in the horizontal plane is greater than vertical movements.
pop_permutation array.Definition at line 838 of file m_popul.f90.
| subroutine the_population::population_subject_predator_attack | ( | class(population), intent(inout) | this, |
| class(predator), intent(in) | this_predator, | ||
| integer, intent(in), optional | time_step_model | ||
| ) |
Subject the population to an attack by a specific predator. The predator acts on agents in its proximity and takes account of the predation confusion and dilution effects (see the_environment::predator::risk_fish_group()).
prey_index is the partial index of the prey agents that are in proximity of this predator.
Preparations: Check optional time step parameter. If not provided, use global commondata::global_time_step_model_current parameter value.
First, calculate the risk of predation from this specific predator to each of the agents in the population using the the_environment::predator::risk_fish_group() method. The "raw" indexed output scheme is used here to avoid multiple cycling over the whole large population of agents, only the agents that are closest to the predator are processed and attacked (maximum number is equal to the index limit commondata::predator_risk_group_select_index_partial).
Second, cycle through all the agents in close proximity of the predator, up to the maximum size of partial indexing parameter commondata::predator_risk_group_select_index_partial. The predator then stochastically attacks each of these agents with the probability equal to the risk of predation. If the attack is successful, the agent the_genome::individual_genome::dies() and loop is exited because the predator is assumed to catch only one agent at a time.
Definition at line 1008 of file m_popul.f90.
| subroutine the_population::population_subject_other_risks | ( | class(population), intent(inout) | this | ) |
Subject the population to mortality caused by habitat-specific mortality risk. Each agent is affected by the risk associated with the habitat it is currently in.
All agents in the population are randomly subjected to the mortality risk the_environment::habitat::risk_mortality that is linked to the habitat object the agent is currently in in a loop.
If the agent is unhappy and is subjected to mortality event, it immediately the_genome::individual_genome::dies().
Definition at line 1102 of file m_popul.f90.
| subroutine the_population::population_subject_individual_risk_mortality | ( | class(population), intent(inout) | this | ) |
Subject all members of this population to their individual mortality risks.
The procedure is simple, loop over all individual agents in the population and stochastically call the_genome::individual_genome::dies() method with probability equal to individual mortality of the agent.
Definition at line 1138 of file m_popul.f90.
| subroutine the_population::population_lifecycle_step_preevol | ( | class(population), intent(inout) | this | ) |
This procedure performs a single step of the life cycle of the whole population, the agents for the step are selected in a random order.
inds_order is an array that sets the order in which the agents are being drawn out of the population to perform the step.ind_seq is the sequential number of the agent as drawn from the population; it is the loop control counter variable.
ind_real is the real sequential number of the agent in the population; this real id is obtained from the order array inds_order.First, an ordering array inds_order is calculated that sets the order in which the agents are drawn from the population. In the simplest case, the order of the agents is random, so this array is actually an array of random integers. The procedure PERMUTE_RANDOM from HEDTOOLS is used here then.
The agents can also be processed in any non-random order. This would require invoking an array indexing procedure ARRAY_INDEX instead of PERMUTE_RANDOM.
For example, to process the agents in the order of the body mass, the ordering array can be obtained obtained as below:
But this code would rank the agents in an increasing order of their body mass. If this is not what is expected, e.g. if the non-random selection is used to mimic a competitive advantage for bigger and heavier agents, a reverse of the ordering is obtained like this:
Second, the agents are drawn from the population, one by one, in the named loop construct INDIVIDUALS.
inds_order ordering array.agent_in index calculates the habitat number where the selected agent is currently in, calling the the_environment::spatial::find_environment() method.
Simple environmental perceptions are obtained: light, depth: the_neurobio::perception::perceptions_environ().
Then, primary motivation values are calculated from the perception components: the_neurobio::appraisal::motivations_primary_calc().
The population-wise maximum motivation value that is used for rescaling is calculated now.
Finally, the age of the agent is incremented to one time step.
Definition at line 1158 of file m_popul.f90.
| subroutine the_population::population_lifecycle_step_eatonly_preevol | ( | class(population), intent(inout) | this | ) |
This procedure performs a single step of the life cycle of the whole population, the agents for the step are selected in a random order.
inds_order is an array that sets the order in which the agents are being drawn out of the population to perform the step.ind_seq is the sequential number of the agent as drawn from the population; it is the loop control counter variable.
ind_real is the real sequential number of the agent in the population; this real id is obtained from the order array inds_order.First, an ordering array inds_order is calculated that sets the order in which the agents are drawn from the population. In the simplest case, the order of the agents is random, so this array is actually an array of random integers. The procedure PERMUTE_RANDOM from HEDTOOLS is used here then.
The agents can also be processed in any non-random order. This would require invoking an array indexing procedure ARRAY_INDEX instead of PERMUTE_RANDOM.
For example, to process the agents in the order of the body mass, the ordering array can be obtained obtained as below:
But this code would rank the agents in an *increasing *order of their of their body mass. If this is not what is expected, e.g. if the non-random selection is used to mimic a competitive advantage for bigger and heavier agents, a reverse of the ordering is obtained like this:
Second, the agents are drawn from the population, one by one, in the named loop construct INDIVIDUALS.
inds_order ordering array.agent_in index calculates the habitat number where the selected agent is currently in, calling the the_environment::spatial::find_environment() method.
Simple environmental perceptions are obtained: light, depth: the_neurobio::perception::perceptions_environ().
Then, primary motivation values are calculated from the perception components: the_neurobio::appraisal::motivations_primary_calc().
The population-wise maximum motivation value that is used for rescaling is calculated now.
Finally, the age of the agent is incremented to one time step.
Definition at line 1356 of file m_popul.f90.
| subroutine the_population::population_save_data_all_agents_csv | ( | class(population), intent(in) | this, |
| character(len=*), intent(in) | csv_file_name, | ||
| logical, intent(in), optional | save_header, | ||
| logical, intent(in), optional | is_logging, | ||
| logical, intent(out), optional | is_success | ||
| ) |
Save data for all agents within the population into a CSV file.
| [in] | csv_file_name | csv_file_name is the name of the CSV output file. |
| [in] | save_header | save_header turn ON/OFF of the descriptive file header. Header is saved into the first row of the CSV output file If not present, default is FALSE. |
| [in] | is_logging | is_logging turn ON/OFF writing the file name and data into the logger. If not present, default is TRUE if it is the debug mode. |
| [out] | is_success | is_success Flag showing that data save was successful (if TRUE). |
handle_csv is the CSV file handle object defining the file name, Fortran unit and error descriptor, see HEDTOOLS manual for details.csv_record_tmp is the temporary character string that keeps the whole record of the file, i.e. the whole row of the spreadsheet table.
COLUMNS is a parameter array that keeps all column headers; its size is equal to the total number of variables (columns) in the data spreadsheet file.handle_csv is now used as the file identifier.Open the output file defined by the handle_csv handle object for writing.
save_header flag is set to TRUE, save the CSV file header.csv_record_tmp that keeps the whole record (row) of data in the output CSV data file. The length of this string should be enough to fit all the record data, otherwise the record is truncated.csv_record_tmp character string variable is produced such that it can fit the whole record;logging_enabled is TRUE).The CSV output data file can be optionally compressed with the commondata::cmd_zip_output command if commondata::is_zip_outputs is set to TRUE.
Definition at line 1554 of file m_popul.f90.
| subroutine the_population::population_save_data_all_genomes | ( | class(population), intent(in) | this, |
| character(len=*), intent(in) | csv_file_name, | ||
| logical, intent(out), optional | is_success | ||
| ) |
Save the genome data of all agents in this population to a CSV file.
| [in] | csv_file_name | csv_file_name is the name of the CSV output file. |
| [out] | is_success | is_success Flag showing that data save was successful (if TRUE). |
First, determine the number of columns in the data file. The number of columns is calculated by unwinding the whole data structure
chromosome(j,k)allele(l)allele_value(m)See the_genome for more details on the data structure.
The array of the column names is then allocated to the above number.
The column names are built again by unwinding the whole genome data structure into a linear sequence. The column names are like this:
CRO_1_1_ALE_01_AC_1, CRO_1_1_ALE_01_AC_2, CRO_1_1_ALE_01_AC_3, ...
First, the file is opened for writing.
The first record of the data that contains the column names is then "appended" into the complete record and written to the file. The length of this record is calculated based on the length of the columns and their number.
This first line consisting of column names is then written to the output file.
The maximum length of the data record is calculated as the maximum string length of a single data value multiplied by the number of columns. Because the record also adds separators, the number of columns multiplied by three is added to this value.
Finally, cycle over all individuals in this population and save the genome data. The first two columns are the_genome::individual_genome::person_number and the_genome::individual_genome::genome_label. The other columns "unwind" the genome data structure over the inner loops for chromosomes, homologues, alleles and allele components.
chromosome(j,k)allele(l)allele_value(m)See the_genome for more details on the data structure.
Once all individuals are saved, the file is closed.
The CSV output data file can be optionally compressed with the commondata::cmd_zip_output command if commondata::is_zip_outputs is set to TRUE.
Definition at line 1841 of file m_popul.f90.
| subroutine the_population::population_load_data_all_genomes | ( | class(population), intent(inout) | this, |
| integer, intent(in) | pop_size, | ||
| integer, intent(in), optional | pop_number_here, | ||
| character (len=*), intent(in), optional | pop_name_here, | ||
| character(len=*), intent(in) | csv_file_name, | ||
| logical, intent(in), optional | missing_random, | ||
| logical, intent(out), optional | is_success | ||
| ) |
Load the genome data of all agents in this population from a CSV file. Note that the procedure implements several error correcting measures, e.g. checks for minimum number of rows in the file and minimum row length. The input CSV file therefore can include short text notes that are then ignored when reading data.
| [in] | pop_size | pop_size, The size of the population. |
| [in] | pop_number_here | id, Optional numeric population ID. |
| [in] | pop_name_here | descriptor, Optional population string descriptor. |
| [in] | csv_file_name | csv_file_name is the name of the CSV output file. |
| [in] | missing_random | missing_random Flag dictating to generate random genomes if the commondata::popsize parameter exceeds the population size in the CSV genome data size. TRUE = generate random genome, FALSE = leave empty data commondata::unknown |
| [out] | is_success | is_success Flag showing that data save was successful (if TRUE). |
handle_csv is the CSV file handle object defining the file name, Fortran unit and error descriptor, see HEDTOOLS manual for details.line_data_buff is the input data buffer that is being read via the CSV_IO procedure READLINE()n_rows_in is the number of rows in the input CSV file excluding the first row containing the variable names.N_ROWS_MIN is the minimum number of readable rows in the CSV genome data file, if there are less in the file, data are considered invalid.MIN_FILE_INP_LEN is the minimum length of the data row to be included in the read genome.line_data_substrings - an array of row string data values after parding the whole input raw data.matrix_row – array representing the genome data for a single row after parsing the input data file row.Genome data are obtained from the CSV data file provided by the intent(in) parameter csv_file_name.
N_ROWS_MIN. Also check if the file can be read at all. If either of these conditions hold, exit from the procedure withhandle_csv is now used as the file identifier.handle_csv handle object for reading.READLINE function and get the numerical genome data.MIN_FILE_INP_LEN characters are ignored.len_trim(line_data_buff)/MIN_FIELD), so we can now allocate the temporary array of substrings. This is also the total number of variables including the first two non-data records.line_data_buff into an array of individual strings representing each file data field. The number of such non-empty strings (fields) is given by line_data_nflds.line_data_nflds obtained from CSV data coincides with the model (this data structure) as defined by the number of chromosomes, ploidy, chromosome length and N of additive components:
VALUE subroutine.ID_NUMAGENT_NAME.icase) individual agent, note that if any data in the file are abridged, random values are generated within the appropriate genome limits (commondata::allelerange_min, commondata::allelerange_max).icase-s individual into the genome data structure.missing_random determines to initialise all the remaining individuals in the population as random.Initialise all individuals of the population
Definition at line 2040 of file m_popul.f90.
| subroutine the_population::population_save_data_memory | ( | class(population), intent(in) | this, |
| character(len=*), intent(in) | csv_file_name, | ||
| logical, intent(out), optional | is_success | ||
| ) |
Save the perceptual and emotional memory stack data of all agents in this population to a CSV file.
| [in] | csv_file_name | csv_file_name is the name of the CSV output file. |
| [out] | is_success | is_success Flag showing that data save was successful (if TRUE). |
COLUMNS_EMOT defines the column name for all components of the emotional memory stack. They must agree with the components of emotional memory: the_neurobio::memory_emotional.
First, the file csv_file_name is opened for writing.
The maximum length of the data record is calculated from three components
COLUMNS_PERC array for commondata::history_size_perception steps;COLUMNS_EMOT array for commondata::history_size_motivation steps.Note that, because the record also adds separators, such as comma and possibly double quotes, the number of columns multiplied by three is added to this value.
The first record of the data that contains the column names is now being "appended" into the complete record and written to the file. The maximum length of this record is calculated above.
The next portion is composed of the perceptual memory columns from COLUMNS_PERC array for each of the commondata::history_size_perception steps in the memory.
PERC_LIGHT01, PERC_LIGHT02, PERC_LIGHT03, ... PERC_DEPTH01, PERC_DEPTH02, PERC_DEPTH03, ...The third portion is composed of the emotional memory columns from COLUMNS_EMOT array for each of the commondata::history_size_motivation steps in the memory.
MOTIV_HUNGER01, MOTIV_HUNGER02, MOTIV_HUNGER03, ... MOTIV_AVOIDPAS01, MOTIV_AVOIDPAS02, MOTIV_AVOIDPAS03, ....After this step, the first record of column names is ready to be written to the file.
The actual data are written in the same order as above, looping over all individual agents in this population.
The maximum record length record_csv_max_length is here the same as for writing the column headers, it is assumed that any numeric value in the data matrix occupies less than commondata::label_length characters.
So, for each agent, the following data are written with full history:
gos_main is a text value that is undefined (empty string) at the initialisation stage;Each complete record is written to the file as it is built.
Once all individuals are saved, the file is closed.
The CSV output data file can be optionally compressed with the commondata::cmd_zip_output command if commondata::is_zip_outputs is set to TRUE.
Definition at line 2420 of file m_popul.f90.
| subroutine the_population::population_save_data_movements | ( | class(population), intent(in) | this, |
| character(len=*), intent(in) | csv_file_name, | ||
| logical, intent(out), optional | is_success | ||
| ) |
Save the latest movement history of all agents. This method makes use of the the_environment::spatial_moving::history structure that saves latest movements of each agent.
| [in] | csv_file_name | csv_file_name is the name of the CSV output file. |
| [out] | is_success | is_success Flag showing that data save was successful (if TRUE). |
The maximum length of the data record is calculated from three components: (1) commondata::history_size_spatial * 3 columns of X, Y, and depth coordinates plus (2) the same number of separators for these data columns (assuming 3 characters) plus (3) two additional columns that contain the numeric ID of the agent and its string label.
First, the file csv_file_name is opened for writing.
The first record of the data that contains the column names is now being built. The maximum length of this record is calculated above. First thing to do is to cleanup the record string.
After this, the first record is built by appending components.
The first two columns contain the identifiers for each agent:
All remaining columns are built in a loop, by triplets: "X", "Y", "Depth" for each step of the history, up to commondata::history_size_spatial triplets.
Now the first record of column names is ready to be written to the file.
The actual data are written in the same order as above, looping over all individual agents in this population.
Each complete record is written to the file as it is built.
Once all individuals are saved, the file is closed.
The CSV output data file can be optionally compressed with the commondata::cmd_zip_output command if commondata::is_zip_outputs is set to TRUE.
Definition at line 2634 of file m_popul.f90.
| subroutine the_population::population_save_data_behaviours | ( | class(population), intent(in) | this, |
| character(len=*), intent(in) | csv_file_name, | ||
| logical, intent(out), optional | is_success | ||
| ) |
Save the behaviours history stack the_neurobio::behaviour::history_behave for all agents.
| [in] | csv_file_name | csv_file_name is the name of the CSV output file. |
| [out] | is_success | is_success Flag showing that data save was successful (if TRUE). |
The maximum length of the data record is calculated from three components: (1) commondata::history_size_behaviours labels of behaviours plus (2) the same number of separators for these data columns (assuming 3 characters) plus (3) two additional columns that contain the numeric ID of the agent and its string label.
First, the file csv_file_name is opened for writing.
The first record of the data that contains the column names is now being built. The maximum length of this record is calculated above. First thing to do is to cleanup the record string.
After this, the first record is built by appending components.
The first two columns contain the identifiers for each agent:
All remaining columns are built in a loop for each step of the history, up to commondata::history_size_behaviours steps back in history.
Now the first record of column names is ready to be written to the file.
The actual data are written in the same order as above, looping over all individual agents in this population.
Each complete record is written to the file as it is built.
Once all individuals are saved, the file is closed.
The CSV output data file can be optionally compressed with the commondata::cmd_zip_output command if commondata::is_zip_outputs is set to TRUE.
Definition at line 2761 of file m_popul.f90.
| pure subroutine the_population::population_preevol_fitness_calc | ( | class(population), intent(inout) | this | ) |
Calculate fitness for the pre-evolution phase of the genetic algorithm. Pre-evolution is based on selection for a simple criterion without explicit reproduction etc. The criterion for selection at this phase is set by the integer the_individual::individual_agent::fitness component. This procedure provides a whole-population wrapper for the the_individual::individual_agent::fitness_calc() function.
Definition at line 2888 of file m_popul.f90.
| pure integer function the_population::population_ga_reproduce_max | ( | class(population), intent(in) | this | ) |
Determine the number of parents that have fitness higher than the minimum acceptable value. Also, only alive agents are included into the reproducing number.
MIN_FITNESS is the normal limit of the fitness value for inclusion into the reproducing elite group. See also the_individual::individual_agent::individual_preevol_fitness_calc().MIN_GA_REPRODUCE is the minimum GA_REPRODUCE, the final value cannot be smaller than. It is set as the minimum proportion commondata::ga_reproduce_min_prop of the commondata::popsize. However, it cannot be smaller than the absolute minimum commondata::ga_reproduce_n_min.Definition at line 2901 of file m_popul.f90.
| real(srp) function the_population::population_ga_mutation_rate_adaptive | ( | class(population), intent(in) | this, |
| real(srp), intent(in) | baseline, | ||
| real(srp), intent(in), optional | maxvalue | ||
| ) |
This function implements adaptive mutation rate that increases as the population size reduces.
| [in] | baseline | baseline baseline mutation rate |
| [in] | maxvalue | maxvalue maximum mutation rate |
mutationrate_max – the maximum limit to the mutation rate. Can be obtained from the optional parameter maxvalue. The function returns its value at the lowest population size. maxvalue parameter.MUTATIONRATE_MAX_DEF – the default maximum limit to the mutation rate mutationrate_max if maxvalue is not provided.
n_base_point – this is the base value for calculation of the adaptive mutation rate. It can be the number of agents alive or the number of agents that have grown.mutation_grid_abscissa and mutation_grid_ordinate are the arrays that define the interpolation grid for the adaptive mutation rate.MIN_GROWING a parameter setting the minimum number of growing agents in the population. If their actual number is smaller, the mutation rate further incremented by a factor set by the parameterNON_GROW_INCREMENT is an increment factor for the mutation rate in case the number of growing agents is below the lower limit MIN_GROWING.First, calculate the base point n_base_point. This value is the base for the calculation of the adaptive mutation rate.
mutationrate_maxThe n_base_point can be:
mutation_grid_abscissa is an array with three elements:The grid ordinate is defined as
mutationrate_maxMUTATIOlNRATE_MAX) and the minimum (baseline) mutation values; the latter value increments the minimum baseline.baseline dummy parameter.Adaptive mutation rate is calculated based on the DDPINTERPOL() procedure with the grid array set by mutation_grid_abscissa and mutation_grid_ordinate and the interpolation value set by the number of agents that are the_genome::individual_genome::is_alive() in the population. An example pattern of the adaptive mutation rate function is plotted below. Here 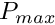 is the maximum mutation rate defined by
is the maximum mutation rate defined by mutationrate_max and 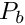 is the baseline (normal, low) mutation rate defined by the
is the baseline (normal, low) mutation rate defined by the baseline parameter.
If the number of agents that had grown from their birth mass is less than the minimum number (MIN_GROWING), mutation rate is incremented by a fixed factor NON_GROW_INCREMENT. However, it is still forced to be within the range [ baseline, mutationrate_max ].
Interpolation plots can be saved in the debug mode using this plotting command: commondata::debug_interpolate_plot_save().
Definition at line 2936 of file m_popul.f90.
|
private |
Definition at line 25 of file m_popul.f90.
| integer, public the_population::global_ind_n_eaten_by_predators |
Global indicator variable that keeps the number of agents that have died as a consequence of predatory attacks. All other dies are therefore caused by starvation.
GENERATIONS_PREEVOL named loop in the_evolution::generations_loop_ga(). Definition at line 183 of file m_popul.f90.