 |
The AHA Model
Revision: 17463
Reference implementation 04 (HEDG02_04)
|
|
The AHA Model
Revision: 17463
Reference implementation 04 (HEDG02_04)
|
Definition of high level behavioural architecture. More...
Data Types | |
| type | behaviour_base |
| Root behaviour abstract type. Several different discrete behaviours encompass the behavioural repertoire of the agent. This is the base root type from which all other behaviours are obtained by inheritance/extension. More... | |
| interface | behaviour_init_root |
| Abstract interface for the deferred init function that has to be overriden by each object that extends the basic behavioural component class. More... | |
| type | move |
| Movement is an umbrella abstract type linked with spatial movement. More... | |
| interface | move_init_root |
| Abstract interface for the deferred init function that has to be overriden by each object that extends the basic behavioural component class. More... | |
| type | eat_food |
| Eat food is consuming food item(s) perceived. More... | |
| type | reproduce |
| Reproduce is do a single reproduction. More... | |
| type | walk_random |
| Walk_random is a single step of a Gaussian random walk. More... | |
| type | freeze |
| Freeze is stop any locomotion completely. More... | |
| type | escape_dart |
| Escape dart is a very fast long distance movement, normally in response to a direct predation threat. More... | |
| type | approach |
| Approach an arbitrary spatial object is a directed movement to an arbitrary the_environment::spatial class target object. More... | |
| type | approach_conspec |
| Approach conspecifics is directed movement towards a conspecific. More... | |
| type | migrate |
| Migrate is move quickly directing to the other habitat More... | |
| type | go_down_depth |
| Go down dive deeper. More... | |
| type | go_up_depth |
| Go up raise to a smaller depth. TODO: abstract type linking both Up and Down. More... | |
| type | debug_base |
| This is a test fake behaviour unit that is used only for debugging. It cannot be "execute"'d, but the expectancy can be calculated (normally in the debug mode). More... | |
| type | behaviour |
| The behaviour of the agent is defined by the the_behaviour::behaviour class. This class defines the behavioural repertoire of the agent. Each of the components of the behavioural repertoire (behaviour object) is defined as a separate independent class with its own self parameter. However, the agent which performs the behaviour (the actor agent) is included as the first non-self parameter into the behaviour component methods. More... | |
| type | architecture_neuro |
| This type is an "umbrella" for all the lower-level classes. More... | |
Functions/Subroutines | |
| pure subroutine | behaviour_root_attention_weights_transfer (this, this_agent) |
Transfer attention weights from the actor agent to the behaviour's GOS expectancy object. At this stage, attention weights for this behaviour's expectancy motivational state components are copied from the actor agent's (this_agent) main motivational components' attention weights. More... | |
| elemental real(srp) function | behaviour_root_gos_expectation (this) |
Accessor get-function for the final expected GOS arousal from this behaviour. All calculations for are done in expectancies_calculate for the specific behaviour unit. More... | |
| elemental logical function | behaviour_root_get_is_executed (this) |
| Get the execution status of the behaviour unit. If TRUE, the unit is currently active and is being executed. This is the "getter" for the_behaviour::behaviour_base::is_active. More... | |
| elemental subroutine | eat_food_item_init_zero (this) |
| Initialise the eat food item behaviour component to a zero state. More... | |
| elemental subroutine | walk_random_init_zero (this) |
| Initialise the walk_random behaviour component to a zero state. More... | |
| elemental subroutine | freeze_init_zero (this) |
| Initialise the freeze behaviour component to a zero state. Freeze is a special type of move to a zero distance / zero speed. More... | |
| subroutine | freeze_do_this (this, this_agent) |
Do freeze by this_agent (the actor agent). Subjective assessment of the motivational value for this is based on the number of food items, conspecifics and predators in the perception object. More... | |
| subroutine | freeze_motivations_expect (this, this_agent, time_step_model, rescale_max_motivation) |
the_behaviour::freeze::motivations_expect() (re)calculates motivations from fake expected perceptions following from the procedure freeze::do_this() => the_behaviour::freeze_do_this(). More... | |
| subroutine | freeze_do_execute (this, this_agent) |
Execute this behaviour component "freeze" by this_agent agent. More... | |
| elemental subroutine | escape_dart_init_zero (this) |
| Initialise the escape dart behaviour component to a zero state. Dart is a quick high speed active escape. More... | |
| subroutine | escape_dart_do_this (this, this_agent, predator_object, dist_is_stochastic, time_step_model) |
Do active escape dart by this_agent (the actor agent). Subjective assessment of the motivational value for this is based on the distance of escape (in turn, dependent on the visibility of the predator). More... | |
| subroutine | escape_dart_motivations_expect (this, this_agent, predator_object, time_step_model, rescale_max_motivation) |
escape_dart::motivations_expect() is a subroutine (re)calculating motivations from fake expected perceptions following from the procedure escape_dart::do_this() => the_behaviour::escape_dart_do_this(). More... | |
| subroutine | escape_dart_do_execute (this, this_agent, predator_object, environment_limits) |
Execute this behaviour component "escape" by this_agent agent. More... | |
| elemental subroutine | approach_spatial_object_init_zero (this) |
| Initialise the approach behaviour component to a zero state. Approach is a generic type but not abstract. More... | |
| subroutine | approach_do_this (this, this_agent, target_object, target_offset, predict_window_food, time_step_model) |
The "do" procedure component of the behaviour element performs the behaviour without affecting the actor agent (the_agent) and the world (here food_item_eaten) which have intent(in), so it only can change the internal representation of the behaviour (the type to which this procedure is bound to, here APPROACH). More... | |
| subroutine | approach_motivations_expect (this, this_agent, target_object, target_offset, time_step_model, rescale_max_motivation) |
the_behaviour::approach::expectancies_calculate() (re)calculates motivations from fake expected perceptions following from the procedure approach::do_this() => the_behaviour::approach_do_this(). More... | |
| subroutine | approach_do_execute (this, this_agent, target_object, is_random, target_offset, environment_limits) |
Execute this behaviour component "approach" by this_agent agent. More... | |
| elemental subroutine | approach_conspecifics_init_zero (this) |
Initialise the approach conspecific behaviour to a zero state. Approach conspecific is a special extension of the generic APPROACH behaviour. More... | |
| subroutine | approach_conspecifics_do_this (this, this_agent, target_object, target_offset, predict_window_food, time_step_model) |
The "do" procedure component of the behaviour element performs the behaviour without affecting the actor agent (the_agent) and the world (here food_item_eaten) which have intent(in), so it only can change the internal representation of the behaviour (the type to which this procedure is bound to, here APPROACH_CONSPEC). More... | |
| subroutine | approach_conspecifics_motivations_expect (this, this_agent, target_object, target_offset, time_step_model, rescale_max_motivation) |
the_behaviour::approach_conspec::expectancies_calculate() (re)calculates motivations from fake expected perceptions following from the procedure the_behaviour::approach_conspec::do_this(). More... | |
| elemental subroutine | migrate_init_zero (this) |
| Initialise the migrate behaviour component to a zero state. More... | |
| subroutine | migrate_do_this (this, this_agent, target_env, predict_window_food, predict_window_consp, predict_window_pred, time_step_model) |
The "do" procedure component of the behaviour element performs the behaviour without affecting the actor agent (the_agent) and the world (here food_item_eaten) which have intent(in), so it only can change the internal representation of the behaviour (the type to which this procedure is bound to, here MIGRATE). More... | |
| subroutine | migrate_motivations_expect (this, this_agent, target_env, predict_window_food, predict_window_consp, predict_window_pred, time_step_model, rescale_max_motivation) |
the_behaviour::migrate::expectancies_calculate() (re)calculates motivations from fake expected perceptions following from the procedure migrate::do_this(). More... | |
| subroutine | migrate_do_execute (this, this_agent, target_env) |
Execute this behaviour component "migrate" by this_agent agent. More... | |
| pure real(srp) function | hope (baseline, memory_old, memory_new, zero_hope, maximum_hope, raw_grid_x, raw_grid_y) |
| The hope function for the assessment of expectancy for a completely novel stimulus or environment for which local information is absent. More... | |
| elemental real(srp) function | depth_walk_default (length, walk_factor) |
| Calculate the default upward and downward walk step size. This function is called from the_behaviour::go_down_do_this() and the_behaviour::go_down_motivations_expect() if the upwards or downwards walk size is not provided explicitly. More... | |
| elemental subroutine | go_down_depth_init_zero (this) |
| Initialise the go down to a deeper spatial layer behaviour component to a zero state. More... | |
| subroutine | go_down_do_this (this, this_agent, max_depth, depth_walk, predict_window_food, time_step_model) |
Do go down by this_agent (the actor agent). Subjective assessment of the motivational value for this is based on the number of food items, conspecifics and predators at the layers below the this_agent actor agent. More... | |
| subroutine | go_down_motivations_expect (this, this_agent, depth_walk, max_depth, environments, time_step_model, rescale_max_motivation) |
go_down_depth::motivations_expect() is a subroutine (re)calculating motivations from fake expected perceptions following from the procedure go_down_depth::do_this() => the_behaviour::go_down_do_this(). More... | |
| subroutine | go_down_do_execute (this, this_agent, max_depth, environments, depth_walk) |
Execute this behaviour component "go down" by this_agent agent. More... | |
| elemental subroutine | go_up_depth_init_zero (this) |
| Initialise the go up to a shallower spatial layer behaviour component to a zero state. More... | |
| subroutine | go_up_do_this (this, this_agent, min_depth, depth_walk, predict_window_food, time_step_model) |
Do go up by this_agent (the actor agent). Subjective assessment of the motivational value for this is based on the number of food items, conspecifics and predators at the layers below the this_agent actor agent. More... | |
| subroutine | go_up_motivations_expect (this, this_agent, depth_walk, min_depth, environments, time_step_model, rescale_max_motivation) |
go_up_depth::motivations_expect() is a subroutine (re)calculating motivations from fake expected perceptions following from the procedure go_up_depth::do_this() => the_behaviour::go_up_do_this(). More... | |
| subroutine | go_up_do_execute (this, this_agent, min_depth, environments, depth_walk) |
Execute this behaviour component "go up" by this_agent agent towards. More... | |
| elemental subroutine | debug_base_init_zero (this) |
| Initialise the fake debug behaviour behaviour component to a zero state. More... | |
| subroutine | debug_base_motivations_expect (this, this_agent, time_step_model, rescale_max_motivation) |
the_behaviour::debug_base::motivations_expect() is a subroutine (re)calculating motivations from fake expected perceptions for the fake debug behaviour. More... | |
| subroutine | eat_food_item_do_this (this, this_agent, food_item_eaten, time_step_model, distance_food_item, capture_prob, is_captured) |
Eat a food item defined by the object food_item_eaten. The "do" procedure component of the behaviour element performs the behaviour without affecting the actor agent (the_agent) and the world (here food_item_eaten) which have intent(in), so it only can change the internal representation of the behaviour (the type to which this procedure is bound to, here the_behaviour::eat_food). So, here the result of this procedure is assessment of the stomach content increment and body mass increment that would result from eating the this food item by the this_agent. The main output from this do procedure is the this behavioural unit, namely two of its internal data components: More... | |
| subroutine | eat_food_item_motivations_expect (this, this_agent, food_item_eaten, time_step_model, distance_food_item, capture_prob, rescale_max_motivation) |
eat_food::motivations_expect() is a subroutine (re)calculating motivations from fake expected perceptions following from the procedure eat_food::do_this() => the_behaviour::eat_food_item_do_this(). More... | |
| subroutine | eat_food_item_do_execute (this, this_agent, food_item_eaten, food_resource_real, eat_is_success) |
Execute this behaviour component "eat food item" by this_agent agent towards the food_item_eaten. More... | |
| elemental subroutine | reproduce_init_zero (this) |
| Initialise reproduce behaviour object. More... | |
| integer function | maximum_n_reproductions (this) |
| Calculate the maximum number of possible reproductions for this agent. It is assumed that a male can potentially fertilise several females that are within its perception object (in proximity) during a single reproduction event. For females, this number if always one. More... | |
| subroutine | reproduce_do_this (this, this_agent, p_reproduction, is_reproduce) |
Do reproduce by this_agent (the actor agent) given the specific probability of successful reproduction. The probability of reproduction depends on the number of agents of the same and of the opposite sex within the visual range of the this agent weighted by the difference in the body mass between the actor agent and the average body mass of the other same-sex agents. The main output from this do procedure is the this behavioural unit object, namely its two components: More... | |
| subroutine | reproduce_motivations_expect (this, this_agent, time_step_model, reprod_prob, non_stochastic, rescale_max_motivation) |
reproduce::motivations_expect() is a subroutine (re)calculating motivations from fake expected perceptions following from reproduce::do_this() => the_behaviour::reproduce_do_this() procedure. More... | |
| subroutine | reproduce_do_execute (this, this_agent) |
Execute this behaviour component "reproduce" by the this_agent agent. More... | |
| subroutine | walk_random_do_this (this, this_agent, distance, distance_cv, predict_window_pred, predict_window_food, time_step_model) |
The "do" procedure component of the behaviour element performs the behaviour without affecting the actor agent (the_agent) and the world (here food_item_eaten) which have intent(in), so it only can change the internal representation of the behaviour (the type to which this procedure is bound to, here WALK_RANDOM). More... | |
| subroutine | walk_random_motivations_expect (this, this_agent, distance, distance_cv, predict_window_pred, predict_window_food, time_step_model, rescale_max_motivation) |
the_behaviour::walk_random::expectancies_calculate() (re)calculates motivations from fake expected perceptions following from the procedure walk_random::do_this() => the_behaviour::walk_random_do_this(). More... | |
| subroutine | walk_random_do_execute (this, this_agent, step_dist, step_cv, environment_limits) |
Execute this behaviour component "random walk" by this_agent agent. More... | |
| elemental subroutine, private | behaviour_whole_agent_init (this) |
| Initialise the behaviour components of the agent, the the_behaviour::behaviour class. More... | |
| elemental subroutine | behaviour_whole_agent_deactivate (this) |
| Deactivate all behaviour units that compose the behaviour repertoire of the agent. More... | |
| elemental character(len=label_length) function | behaviour_get_behaviour_label_executing (this) |
Obtain the label of the currently executing behaviour for the this agent. More... | |
| integer function | behaviour_select_conspecific (this, rescale_max_motivation) |
| Select the optimal conspecific among (possibly) several ones that are available in the perception object of the agent. More... | |
| integer function | behaviour_select_conspecific_nearest (this) |
| Select the nearest conspecific among (possibly) several ones that are available in the perception object. Note that conspecifics are sorted by distance within the perception object. Thus, this procedure just selects the first conspecific. More... | |
| integer function | behaviour_select_food_item (this, rescale_max_motivation) |
| Select the optimal food item among (possibly) several ones that are available in the perception object of the agent. More... | |
| integer function | behaviour_select_food_item_nearest (this) |
Select the nearest food item among (possibly) several ones that are available in the perception object. This is a specific and most simplistic version of the behaviour_select_food_item function: select the nearest food item available in the agent's perception object. Because the food items are sorted within the perception object just select the first item. More... | |
| subroutine | behaviour_do_eat_food_item (this, number_in_seen, food_resource_real) |
| Eat a specific food item that are found in the perception object. More... | |
| subroutine | behaviour_do_reproduce (this) |
Reproduce based on the this agent's current state. More... | |
| subroutine | behaviour_do_walk (this, distance, distance_cv) |
| Perform a random Gaussian walk to a specific average distance with certain variance (set by the CV). More... | |
| subroutine | behaviour_do_freeze (this) |
| Perform (execute) the the_behaviour::freeze behaviour. More... | |
| subroutine | behaviour_do_escape_dart (this, predator_object) |
| Perform (execute) the the_behaviour::escape_dart behaviour. More... | |
| subroutine | behaviour_do_approach (this, target_object, is_random, target_offset) |
| Approach a specific the_environment::spatial class target, i.e. execute the the_behaviour::approach behaviour. The target is either a conspecific from the perception (the_neurobio::conspec_percept_comp class) or any arbitrary the_environment::spatial class object. More... | |
| subroutine | behaviour_do_migrate (this, target_env) |
| Perform (execute) the the_behaviour::migrate (migration) behaviour. More... | |
| logical function | behaviour_try_migrate_random (this, target_env, max_dist, prob) |
| Perform a simplistic random migration. If the agent is within a specific distance to the target environment, it emigrates there with a specific fixed probability. More... | |
| subroutine | behaviour_do_go_down (this, depth_walk) |
| Perform (execute) the the_behaviour::go_down_depth (go down) behaviour. More... | |
| subroutine | behaviour_do_go_up (this, depth_walk) |
| Perform (execute) the the_behaviour::go_up_depth (go up) behaviour. More... | |
| elemental subroutine | behaviour_cleanup_history (this) |
| Cleanup the behaviour history stack for the agent. All values are empty. More... | |
| subroutine | behaviour_select_optimal (this, rescale_max_motivation, food_resource_real) |
| Select and execute the optimal behaviour, i.e. the behaviour which minimizes the expected GOS arousal. More... | |
| subroutine | behaviour_select_fixed_from_gos (this, rescale_max_motivation, food_resource_real) |
| Select and execute behaviour based on the current global organismic state. This procedure is significantly different from the_behaviour::behaviour_select_optimal() in that the behaviour that is executed is not based on optimisation of the expected GOS. Rather, the current GOS fully determines which behaviour unit is executed. Such a rigid link necessarily limits the range of behaviours that could be executed. More... | |
| elemental subroutine, private | neurobio_init_components (this) |
| Initialise neuro-biological architecture. More... | |
Variables | |
| character(len= *), parameter, private | modname = "(THE_BEHAVIOUR)" |
Definition of high level behavioural architecture.
This module defines the behavioural architecture of the agent, extending the starting neutobiology defined in the_neurobio. Various behavioural actions are implemented that form the behavioural repertoire of the agent.
| pure subroutine the_behaviour::behaviour_root_attention_weights_transfer | ( | class(behaviour_base), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent | ||
| ) |
Transfer attention weights from the actor agent to the behaviour's GOS expectancy object. At this stage, attention weights for this behaviour's expectancy motivational state components are copied from the actor agent's (this_agent) main motivational components' attention weights.
associate construct makes it easier to write all possible combinations, so there is little need to implement motivation-state specific attention transfer functions separately. Here in the below associate constructs EX is the this expectancy class root and AG is the actor agent class root. STATE_MOTIVATION_BASE because specific motivation states (hunger,...) are still unavailable at this level, but we are intended to get access to specific motivational state of the actor agent. The state_motivation_attention_weights_transfer procedure in STATE_MOTIVATION_BASE class just implements attention weights transfer across two motivation state root class objects. Even so, we still would need this function here calling specific motivation object-bound versions. However, this is more complicated than just a single subroutine as implemented here for the BEHAVIOUR_BASE. Anyway, we only really copy attention weights for all motivation states in a single batch here and never need it elsewhere. MOTIVATION class, hunger, fear_defence etc.Transfer attention weights for hunger.
STATE_MOTIVATION_BASE bound procedure that implements this attention transfer is: call thisexpectancyhungerattention_copy( & this_agentmotivationshunger)Transfer attention weights for fear_defence.
STATE_MOTIVATION_BASE bound procedure that implements this attention transfer is: call thisexpectancyfear_defenceattention_copy( & this_agentmotivationsfear_defence)Transfer attention weights for reproduction.
STATE_MOTIVATION_BASE bound procedure that implements this attention transfer is: call thisexpectancyreproductionattention_copy( & this_agentmotivationsreproduction)Definition at line 669 of file m_behav.f90.
| elemental real(srp) function the_behaviour::behaviour_root_gos_expectation | ( | class(behaviour_base), intent(in) | this | ) |
Accessor get-function for the final expected GOS arousal from this behaviour. All calculations for are done in expectancies_calculate for the specific behaviour unit.
| [in] | this | this self. |
Definition at line 745 of file m_behav.f90.
| elemental logical function the_behaviour::behaviour_root_get_is_executed | ( | class(behaviour_base), intent(in) | this | ) |
Get the execution status of the behaviour unit. If TRUE, the unit is currently active and is being executed. This is the "getter" for the_behaviour::behaviour_base::is_active.
Definition at line 758 of file m_behav.f90.
| elemental subroutine the_behaviour::eat_food_item_init_zero | ( | class(eat_food), intent(inout) | this | ) |
Initialise the eat food item behaviour component to a zero state.
First init components from the base root class the_behaviour::behaviour_base: Mandatory label component that should be read-only.
The execution status is always FALSE, can be reset to TRUE only when the behaviour unit is called to execution.
And the expectancy type components.
And init the expected arousal data component.
Second, init components of this specific behaviour (EAT_FOOD) component extended class.
Definition at line 774 of file m_behav.f90.
| elemental subroutine the_behaviour::walk_random_init_zero | ( | class(walk_random), intent(inout) | this | ) |
Initialise the walk_random behaviour component to a zero state.
First, initialise components from the base root class the_behaviour::behaviour_base. Mandatory label component that should be read-only.
The execution status is always FALSE, can be reset to TRUE only when the behaviour unit is called to execution.
And the expectancy components.
Abstract MOVE component.
Second, init components of this specific behaviour (WALK_RANDOM).
Definition at line 802 of file m_behav.f90.
| elemental subroutine the_behaviour::freeze_init_zero | ( | class(freeze), intent(inout) | this | ) |
Initialise the freeze behaviour component to a zero state. Freeze is a special type of move to a zero distance / zero speed.
First init components from the base root class the_behaviour::behaviour_base. Mandatory label component that should be read-only.
The execution status is always FALSE, can be reset to TRUE only when the behaviour unit is called to execution.
And the expectancy components.
Abstract MOVE component.
Second, init components of this specific behaviour (FREEZE).
Definition at line 833 of file m_behav.f90.
| subroutine the_behaviour::freeze_do_this | ( | class(freeze), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent | ||
| ) |
Do freeze by this_agent (the actor agent). Subjective assessment of the motivational value for this is based on the number of food items, conspecifics and predators in the perception object.
| [in,out] | this | [inout] this the object itself. |
| [in] | this_agent | this_agent is the actor agent which goes down. |
The expected food gain for freezing is zero as immobile agent does not eat.
Calculate the expected direct risk of predation that is based on the distance to the nearest predator. However, a version of the the_neurobio::perception::risk_pred() procedure for freezing/immobile agent is used here.
Calculate the expected predation risk for the immobile agent. It is assumed that predators that are roaming nearby cannot easily detect an immobile/freezing agent as long as it does not move (freezing here has significant similarity with sheltering). Therefore, the expectancy is based on a (subjective) zero count of the number of predators in the agent's perception object and normal risk component based on the predators in the memory stack. The calculation is done by the standard the_neurobio::predation_risk_backend() function. Thus, the resulting general risk is calculated as:
![\[ R = 0 + r_{id} \cdot (1 - \omega) , \]](form_0.png)
where 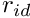 ) is the average number of predators in the latest memory stack and
) is the average number of predators in the latest memory stack and 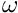 is the weighting factor for the actual number of predators (that is zero in this case).
is the weighting factor for the actual number of predators (that is zero in this case).
Definition at line 862 of file m_behav.f90.
| subroutine the_behaviour::freeze_motivations_expect | ( | class(freeze), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| integer, intent(in), optional | time_step_model, | ||
| real(srp), intent(in), optional | rescale_max_motivation | ||
| ) |
the_behaviour::freeze::motivations_expect() (re)calculates motivations from fake expected perceptions following from the procedure freeze::do_this() => the_behaviour::freeze_do_this().
| [in,out] | this | [inout] this the object itself. |
| [in] | this_agent | this_agent is the actor agent which does freezing. |
| [in] | time_step_model | [in] time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
| [in] | rescale_max_motivation | rescale_max_motivation optional maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
expect_predator is the expected general predation risk, that is based on a weighting of the current predation and predation risk from the memory stack.
Check optional time step parameter. If not provided, use global parameter value from commondata::global_time_step_model_current.
As the first step, we use the do-procedure freeze::do_this() => the_behaviour::freeze_do_this() to perform the behaviour desired without changing either the agent or its environment, obtaining the subjective values of the this behaviour components that later feed into the motivation expectancy functions:
perception_override_pred_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyFirst, calculate the expected stomach contents, body mass and energy reserves out of the fixed zero food gain that is returned from the do_this procedure.
Calculate the expected stomach content, which is decremented by the expected digestion value (the_body::stomach_emptify_backend()).
Second, transfer the predation risk expectancies from the freezing class object to the dedicated override perception variables (their final values are calculated in do_this).
The next step is to calculate the motivational expectancies using the fake perceptions to override the default (actual agent's) values. At this stage, first, calculate motivation values resulting from the behaviour done (freeze::do_this() ) at the previous steps: what would be the motivation values if the agent does perform FREEZE? Technically, this is done by calling the neuronal response function, percept_components_motiv::motivation_components() method, for each of the motivational states with perception_override_ dummy parameters overriding the default values. Here is the list of the fake overriding perceptions for the FREEZE behaviour:
perception_override_pred_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyReal agent perception components are now substituted by the fake values resulting from executing this behaviour (reproduce::do_this() => the_behaviour::reproduce_do_this() method). This is repeated for all the motivations: hunger, fear state etc. These optional override parameters are substituted by the "fake" values.
Next, from the perceptual components calculated at the previous step we can obtain the primary and final motivation values by weighed summing.
Here we can use global maximum motivation across all behaviours and perceptual components if it is provided, for rescaling.
Or can rescale using local maximum value for this behaviour only.
Transfer attention weights from the actor agent this_agent to the this behaviour component. So, we will now use the updated modulated attention weights of the agent rather than their default parameter values.
So the primary motivation values are calculated.
Primary motivations are logged in the debug mode.
There is no modulation at this stage, so the final motivation values are the same as primary motivations.
Finally, calculate the finally expected arousal level for this behaviour. As in the GOS, the overall arousal is the maximum value among all motivation components.
Log also the final expectancy value in the debug mode.
Now as we know the expected arousal, we can choose the behaviour which would minimise this arousal level.
Definition at line 918 of file m_behav.f90.
| subroutine the_behaviour::freeze_do_execute | ( | class(freeze), intent(inout) | this, |
| class(appraisal), intent(inout) | this_agent | ||
| ) |
Execute this behaviour component "freeze" by this_agent agent.
| [in,out] | this_agent | [in] this_agent is the actor agent which goes down. |
As the first step, we use the do-procedure freeze::do_this() to perform the behaviour desired. As a result, the following values are obtained:
However, because freezing does not incur any specific behavioural costs and does not change any environmental objects, calling do_this() is really unnecessary. It is therefore only called in the DEBUG mode to log and check the resulting perception values.
Freezing results in some small cost, equal to a single piece of the the cost of living. However, it is much smaller than the cost of locomotion. Also, no food can be obtained while freezing but digestion still occurs, so the value of the stomach contents is reduced by a fixed fraction. However, freezing, unlike other behaviour components, does not incur any specific cost or change of the agent. Cost of living and digestion subtractions are updated for every time step for every other behaviours anyway. Therefore, it is not done here.
Freezing does not affect the environmental objects.
Definition at line 1221 of file m_behav.f90.
| elemental subroutine the_behaviour::escape_dart_init_zero | ( | class(escape_dart), intent(inout) | this | ) |
Initialise the escape dart behaviour component to a zero state. Dart is a quick high speed active escape.
First init components from the base root class the_behaviour::behaviour_base. Mandatory label component that should be read-only.
The execution status is always FALSE, can be reset to TRUE only when the behaviour unit is called to execution.
And the expectancy components.
Abstract MOVE component.
Second, init components of this specific behaviour (ESCAPE_DART).
Definition at line 1266 of file m_behav.f90.
| subroutine the_behaviour::escape_dart_do_this | ( | class(escape_dart), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| class(spatial), intent(in), optional | predator_object, | ||
| logical, intent(in), optional | dist_is_stochastic, | ||
| integer, intent(in), optional | time_step_model | ||
| ) |
Do active escape dart by this_agent (the actor agent). Subjective assessment of the motivational value for this is based on the distance of escape (in turn, dependent on the visibility of the predator).
| [in] | this_agent | this_agent is the actor agent which goes down. |
| [in] | predator_object | predator_object optional predator object, if present, it is assumed the actor agent tries to actively escape from this specific predator. |
| [in] | dist_is_stochastic | dist_is_stochastic Logical flag, if set to TRUE, the escape distance is stochastic in the expectancy engine; this can define an internal expectation uncertainty. |
| [in] | time_step_model | time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
Check optional time step parameter. If unset, use global commondata::global_time_step_model_current.
The expected food gain for active escape is zero as the agent cannot eat at this time.
First, calculate the distance of escape. The escape distance, in turn, depends on the visibility distance of the predator object: it should exceed this distance, so the actor agent could not see the predator any more.
First, check if the predator object is provided. If the predator object is provided as a dummy parameter, visibility range can be assessed using its size. However, the calculations depend on the exact type of the predator object because it can be the_environment::predator or the_neurobio::spatialobj_percept_comp (in predator perception: the_neurobio::percept_predator) or perhaps even just any extension of the the_environment::spatial class. Fortran select type construct is used here.
object_area parameter is not provided), so the object area is calculated for fish (see the_neurobio::spatialobj_percept_visibility_visual_range()).If the predator object is not provided as a dummy parameter, visibility range is assessed using the default size of the predator commondata::predator_body_size and the ambient illumination at the actor agent's depth.
Knowing the visibility range of the predator, one can calculate the escape distance. Namely, the escape distance is obtained by multiplying the visibility range by the commondata::escape_dart_distance_default_factor parameter constant.
This constant should normally exceed 1.0. In such a case, the escape distance exceeds the visibility of the predator. However, it should not be too long to avoid extra energetic cost.
If the dist_is_stochastic optional parameter is TRUE, the escape distance is stochastic with the mean as above and the coefficient of variation set by the commondata::escape_dart_distance_default_stoch_cv parameter. Stochastic distance can define uncertainty in the escape behaviour expectancy.
Knowing the movement distance, it is possible to calculate the cost of movement to this distance using the the_body::condition_cost_swimming_burst() method assuming the swimming is turbulent (so the exponent parameter takes the commondata::swimming_cost_exponent_turbulent value).
The expected direct risk of predation is assumed to be commondata::zero.
Accordingly, the general risk of predation taking account both the number of predators in the perception object and the average number of predators in the memory stack is calculated using the the_neurobio::predation_risk_backend() method, assuming there are no predators in perception.
Definition at line 1296 of file m_behav.f90.
| subroutine the_behaviour::escape_dart_motivations_expect | ( | class(escape_dart), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| class(spatial), intent(in), optional | predator_object, | ||
| integer, intent(in), optional | time_step_model, | ||
| real(srp), intent(in), optional | rescale_max_motivation | ||
| ) |
escape_dart::motivations_expect() is a subroutine (re)calculating motivations from fake expected perceptions following from the procedure escape_dart::do_this() => the_behaviour::escape_dart_do_this().
| [in] | this_agent | this_agent is the actor agent which goes down. |
| [in] | predator_object | predator_object optional predator object, if present, it is assumed the actor agent tries to actively escape from this specific predator. |
| [in] | time_step_model | time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
| [in] | rescale_max_motivation | rescale_max_motivation maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
expect_predator is the expected general predation risk, that is based on a weighting of the current predation and predation risk from the memory stack.
Check optional time step parameter. If not provided, use global parameter value from commondata::global_time_step_model_current.
As the first step, we use the do-procedure go_down_depth::do_this() => the_behaviour::go_down_do_this() to perform the behaviour desired without changing either the agent or its environment, obtaining the subjective values of the this behaviour components that later feed into the motivation expectancy functions:
perception_override_pred_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyFirst, calculate the expected stomach content, which is decremented by the expected digestion value (the_body::stomach_emptify_backend()).
Second, calculate the expected body mass of the agent as a consequence of the escape movement. The body mass is decremented by the cost of movement to the this%distance and the cost of living (the_body::condition::living_cost()).
The expected energy reserves are calculated from the fake perceptions of the body mass and the current length (length does not change as food intake is zero in case of escape) using the the_body::energy_reserve() function.
The expected direct predation risk is transferred from the this object (the_behaviour::escape_dart).
The expected general predation risk is also transferred from the this object (the_behaviour::escape_dart).
The next step is to calculate the motivational expectancies using the fake perceptions to override the default (actual agent's) values. At this stage, first, calculate motivation values resulting from the behaviour done (the_behaviour::escape_dart::do_this()) at the previous steps: what would be the motivation values if the agent does perform escape? Technically, this is done by calling the neuronal response function, percept_components_motiv::motivation_components() method, for each of the motivational states with perception_override_ dummy parameters overriding the default values. Here is the list of the fake overriding perceptions for the ESCAPE_DART behaviour:
perception_override_pred_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyReal agent perception components are now substituted by the fake values resulting from executing this behaviour (reproduce::do_this() => the_behaviour::reproduce_do_this() method). This is repeated for all the motivations: hunger, passive avoidance, active avoidance etc. These optional override parameters are substituted by the "fake" values.
Next, from the perceptual components calculated at the previous step we can obtain the primary and final motivation values by weighed summing.
Here we can use global maximum motivation across all behaviours and perceptual components if it is provided, for rescaling.
Or can rescale using local maximum value for this behaviour only.
Transfer attention weights from the actor agent this_agent to the this behaviour component. So, we will now use the updated modulated attention weights of the agent rather than their default parameter values.
So the primary motivation values are calculated.
Primary motivations are logged in the debug mode.
There is no modulation at this stage, so the final motivation values are the same as primary motivations.
Finally, calculate the finally expected arousal level for this behaviour. As in the GOS, the overall arousal is the maximum value among all motivation components.
Log also the final expectancy value in the debug mode.
Now as we know the expected arousal, we can choose the behaviour which would minimise this arousal level.
Definition at line 1484 of file m_behav.f90.
| subroutine the_behaviour::escape_dart_do_execute | ( | class(escape_dart), intent(inout) | this, |
| class(appraisal), intent(inout) | this_agent, | ||
| class(spatial), intent(in), optional | predator_object, | ||
| class(environment), intent(in), optional | environment_limits | ||
| ) |
Execute this behaviour component "escape" by this_agent agent.
| [in,out] | this_agent | [in] this_agent is the actor agent which goes down. |
| [in] | predator_object | predator_object optional predator object, if present, it is assumed the actor agent tries to actively escape from this specific predator. |
| [in] | environment_limits | environment_limits Limits of the environment area available for the random walk. The moving object cannot get beyond this limit. If this parameter is not provided, the environmental limits are obtained automatically from the global array the_environment::global_habitats_available. |
As the first step, we use the do-procedure the_behaviour::escape_dart::do_this() to perform the behaviour desired. As a result, the following values are obtained:
In the debug mode, checking and logging the perception values.
Escape involves a random walk. Thus, the first thing is the agent displacement:
the_body::condition::set_mass() for this. the_body::condition::set_length() method to update the body length history stack. However, the value_set parameter here is just the current value. This fake re-setting of the body length is done to keep both mass and length synchronised in their history stack arrays (there is no procedure for only updating history).After resetting the body mass, update energy reserves of the agent, that depend on both the length and the mass.
Check if the agent is starved to death. If yes, the agent can die without going any further.
Escape movement itself does not affect the environmental objects.
Definition at line 1799 of file m_behav.f90.
| elemental subroutine the_behaviour::approach_spatial_object_init_zero | ( | class(approach), intent(inout) | this | ) |
Initialise the approach behaviour component to a zero state. Approach is a generic type but not abstract.
First init components from the base root class the_behaviour::behaviour_base. Mandatory label component that should be read-only.
The execution status is always FALSE, can be reset to TRUE only when the behaviour unit is called to execution.
And the expectancy components.
Abstract MOVE component.
Then init components of this specific behaviour component extended class.
Definition at line 1936 of file m_behav.f90.
| subroutine the_behaviour::approach_do_this | ( | class(approach), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| class(spatial), intent(in) | target_object, | ||
| real(srp), intent(in), optional | target_offset, | ||
| integer, intent(in), optional | predict_window_food, | ||
| integer, intent(in), optional | time_step_model | ||
| ) |
The "do" procedure component of the behaviour element performs the behaviour without affecting the actor agent (the_agent) and the world (here food_item_eaten) which have intent(in), so it only can change the internal representation of the behaviour (the type to which this procedure is bound to, here APPROACH).
| [in] | this_agent | this_agent is the actor agent which eats the food item. |
| [in] | target_object | target_object is the spatial target object the actor agent is going to approach. |
| [in] | target_offset | target_offset is an optional offset for the target, so that the target position of the approaching agent does not coincide with the target object. If absent, a default value set by the commondata::approach_offset_default is used. |
| [in] | predict_window_food | predict_window_food the size of the prediction window, i.e. how many steps back in memory are used to calculate the predicted food gain. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | time_step_model | time_step_model optional time step of the model, overrides the value calculated from the spatial data. This parameter is not used for this class, it is here only to allow placement of this parameter for higher-order derived classes. |
Check the optional parameter for the target offset and set the default one if offset is not provided.
The agent approaches the conspecific but to a nonzero distance equal to the target offset value (target_offset). A check is done if the distance between the agent and the conspecific target object is actually smaller than the target offset.
The approach distance is set to zero.
target_offset. (Note that whenever the default target offset is set, i.e. an average of the agent and target body sizes, the approach distance depends on the body sizes of both parties; it is also symmetric, i.e. the same if a large agent approaches a small target conspecific or vice versa.)Definition at line 1965 of file m_behav.f90.
| subroutine the_behaviour::approach_motivations_expect | ( | class(approach), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| class(spatial), intent(in), optional | target_object, | ||
| real(srp), intent(in), optional | target_offset, | ||
| integer, intent(in), optional | time_step_model, | ||
| real(srp), intent(in), optional | rescale_max_motivation | ||
| ) |
the_behaviour::approach::expectancies_calculate() (re)calculates motivations from fake expected perceptions following from the procedure approach::do_this() => the_behaviour::approach_do_this().
| [in] | this_agent | this_agent is the actor agent which does approach. |
| [in] | target_object | target_object is the spatial target object the actor agent is going to approach. |
| [in] | target_offset | target_offset is an optional offset for the target, so that the target position of the approaching agent does not coincide with the target object. If absent, a default value set by the commondata::approach_offset_default is used. |
| [in] | time_step_model | time_step_model optional time step of the model, overrides the value calculated from the spatial data. This parameter is not used for this class, it is here only to allow placement of this parameter for higher-order derived classes. |
| [in] | rescale_max_motivation | rescale_max_motivation optional maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
perception_override_energy is the expected energy reserves as a consequence of the escape movement. Calculated from the body mass and weight.
As the first step, we use the do-procedure walk_random::do_this() => the_behaviour::walk_random_do_this() to perform the behaviour desired without changing either the agent or its environment, obtaining the subjective values of the this behaviour components that later feed into the motivation expectancy functions:
perception_override_bodymassperception_override_energyBody mass: the body mass perception override is obtained by subtracting the approach movement cost and the the_body::condition::living_cost() from the current mass.
Energy: The fake perception values for the energy reserves (perception_override_energy) using the the_body::energy_reserve() procedure.
The next step is to calculate the motivational expectancies using the fake perceptions to override the default (actual agent's) values. At this stage, first, calculate motivation values resulting from the behaviour done (walk_random::do_this() ) at the previous steps: what would be the motivation values if the agent does perform APPROACH? Technically, this is done by calling the neuronal response function, percept_components_motiv::motivation_components() method, for each of the motivational states with perception_override_ dummy parameters overriding the default values. Here is the list of the fake overriding perceptions for the APPROACH behaviour:
perception_override_bodymassperception_override_energyReal agent perception components are now substituted by the fake values resulting from executing this behaviour (approach::do_this() method). This is repeated for all the motivations: hunger, passive avoidance, fear state etc. These optional override parameters are substituted by the "fake" values.
Next, from the perceptual components calculated at the previous step we can obtain the primary and final motivation values by weighed summing.
Here we can use global maximum motivation across all behaviours and perceptual components if it is provided, for rescaling.
Or can rescale using local maximum value for this behaviour only.
Transfer attention weights from the actor agent this_agent to the this behaviour component. So, we will now use the updated modulated attention weights of the agent rather than their default parameter values.
So the primary motivation values are calculated.
Primary motivations are logged in the debug mode.
There is no modulation at this stage, so the final motivation values are the same as primary motivations.
Finally, calculate the finally expected arousal level for this behaviour. As in the GOS, the overall arousal is the maximum value among all motivation components.
Log also the final expectancy value in the debug mode.
Now as we know the expected arousal, we can choose the behaviour which would minimise this arousal level.
Definition at line 2072 of file m_behav.f90.
| subroutine the_behaviour::approach_do_execute | ( | class(approach), intent(inout) | this, |
| class(appraisal), intent(inout) | this_agent, | ||
| class(spatial), intent(in) | target_object, | ||
| logical, intent(in), optional | is_random, | ||
| real(srp), intent(in), optional | target_offset, | ||
| class(environment), intent(in), optional | environment_limits | ||
| ) |
Execute this behaviour component "approach" by this_agent agent.
| [in,out] | this_agent | [in] this_agent is the actor agent which eats the food item. |
| [in] | target_object | target_object is the spatial target object the actor agent is going to approach. |
| [in] | is_random | is_random indicator flag for random correlated walk. If present and is TRUE, the agent approaches to the target_object in form of random correlated walk (see the_environment::spatial_moving::corwalk()), otherwise directly. |
| [in] | target_offset | target_offset is an optional offset for the target, so that the target position of the approaching agent does not coincide with the target object. If absent, a default value set by the commondata::approach_offset_default is used. For the the_behaviour::approach_conspec, the default value is as an average of the agent and target conspecific body lengths. |
| [in] | environment_limits | environment_limits Limits of the environment area available for the random walk. The moving object cannot get beyond this limit. |
First, check the optional parameters
is_random; if the parameter is not provided, the default value FALSE is set so that the agent does a direct approach towards the target object leaving the target offset distance.target offset: target_offset. Note that setting the default value for the target offset involves calling the select type construct. Therefore, the default offset for a simple the_behaviour::approach behaviour is equal to the fixed commondata::approach_offset_default value whereas for the the_behaviour::approach_conspec, it is set as an average of the agent and target conspecific body lengths.
Second, copy the spatial location of the target target_object to a temporary spatial object target_object_tmp to avoid multiple calling the the_environment::spatial::position() method.
target_object is class and getting location can be only done through the location method.First, we use the intent-in do-procedure the_behaviour::approach::do_this() to perform the behaviour desired. Here it calculates the distance towards the target object also taking account of the offset parameter.
Also check here if the approach distance exceeds the limit set by the commondata::migrate_dist_max_step parameter. If it does exceed, the agent will move towards the target object, but the distance is reduced according to the limit.
Relocate to the target object can be either a correlated random walk in the target direction or direct movement to the target.
environment_limits parameter or obtained automatically from the global array the_environment::global_habitats_available.is_random parameter is FALSE), the agent goes directly towards the target. It actually relocates to a spatial position with the the target offset. The new position of the agent is defined by the the_environment::offset_dist() function subtracting the value of the offset.Additionally, also call the the_body::condition::set_length() method to update the body length history stack. However, the value_set parameter here is just the current value. This fake re-setting of the body length is done to keep both mass and length synchronised in their history stack arrays (there is no procedure for only updating history).
Finally, check if the agent is starved to death. If yes, the agent can die without going any further.
Approach does not affect the environmental objects.
Definition at line 2345 of file m_behav.f90.
| elemental subroutine the_behaviour::approach_conspecifics_init_zero | ( | class(approach_conspec), intent(inout) | this | ) |
Initialise the approach conspecific behaviour to a zero state. Approach conspecific is a special extension of the generic APPROACH behaviour.
First init components from the base root class the_behaviour::behaviour_base. Mandatory label component that should be read-only.
The execution status is always FALSE, can be reset to TRUE only when the behaviour unit is called to execution.
And the expectancy components.
Abstract MOVE component.
Component of APPROACH class. Then init components of this specific behaviour component extended class.
This class, APPROACH_CONSPEC, initialisations.
Definition at line 2587 of file m_behav.f90.
| subroutine the_behaviour::approach_conspecifics_do_this | ( | class(approach_conspec), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| class(spatial), intent(in) | target_object, | ||
| real(srp), intent(in), optional | target_offset, | ||
| integer, intent(in), optional | predict_window_food, | ||
| integer, intent(in), optional | time_step_model | ||
| ) |
The "do" procedure component of the behaviour element performs the behaviour without affecting the actor agent (the_agent) and the world (here food_item_eaten) which have intent(in), so it only can change the internal representation of the behaviour (the type to which this procedure is bound to, here APPROACH_CONSPEC).
| [in] | this_agent | this_agent is the actor agent which approaches. |
| [in] | target_object | target_object is the target conspecific the actor agent is going to approach. |
| [in] | target_offset | target_offset is an optional offset for the target, so that the target position of the approaching agent does not coincide with the target object. If absent, a default value set by the commondata::approach_offset_default is used. |
| [in] | predict_window_food | predict_window_food the size of the prediction window, i.e. how many steps back in memory are used to calculate the predicted food gain. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | time_step_model | time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
target_position_agent - the target position of the agent, it does not coincide with the position of the target conspecific and is smaller by the value of the target offset.
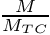 .
.Check optional parameter for the food perception memory window. If the predict_window_food dummy parameter is not provided, its default value is the proportion of the whole perceptual memory window defined by commondata::history_perception_window_food. Thus, only the latest part of the memory is used for the prediction of the future food gain.
Check optional time step parameter. If unset, use global commondata::global_time_step_model_current.
Set the debug plot file name that will be passed to the predator-class-bound function the_environment::predator::risk_fish().
Get the properties of the conspecific from the perception object or real physical conspecific data. This is done by determining the target_object data type with "`select type`" construct (named construct GET_TARGET).
The distance to the target conspecific is determined from the target object with the_neurobio::conspec_percept_comp::get_dist() for perception object or the_environment::spatial::distance() for real conspecific.
target_object is a conspecific from the perception object, its body length and mass are obtained from the respective data components of the_neurobio::conspec_percept_comp.target_object is real conspecific (the_neurobio::appraisal class), its body length and mass are obtained from lower order class component the_body::condition::get_length() and the_body::condition::get_mass() methods.target_object is neither a perception object nor real conspecific, get the location from the commondata::spatial class position data and other properties of the conspecific from the actor agent itself. Such a situation of undefined target type is unexpected and is likely to point to a bug. Therefore, an error is issued into the logger.Target offset target_offset can be provided as an optional dummy parameter to this procedure. However, if it is not provided explicitly, a default value is set as an average of the actor agent body length and the target conspecific body length.
The agent approaches the conspecific but to a nonzero distance equal to the target offset value (target_offset). A check is done if the distance between the agent and the conspecific target object is actually smaller than the target offset.
The approach distance is set to zero.
target_position_agent) after such a zero approach actually coincides with the current position of the agent: it does not plan to swim.target_offset. (Note that whenever the default target offset is set, i.e. an average of the agent and target body sizes, the approach distance depends on the body sizes of both parties; it is also symmetric, i.e. the same if a large agent approaches a small target conspecific or vice versa.)target_position_agent with the offset, using the the_environment::offset_dist() procedure.The expected risk of predation is assumed to reduce due to predator dilution or confusion effects if the agent approaches a conspecific. Furthermore, the risk values depend on the relative positions and distances between the predator and the actor agent and predator and the target conspecific.
Calculation of the expected risks of predation depends on the current perception of the agent. The simplest case is when the agent has currently no predators in its predator perception object:
If there is a non-zero number of predators in the current predator perception, calculations of the expected risks are more complex.
First, get the number of predators in the current perception object using the the_neurobio::percept_predator::get_count().
Accordingly, the general risk of predation taking account both the number of predators in the perception object and the average number of predators in the memory stack is calculated using the the_neurobio::predation_risk_backend() method. However, the expected number of predators is reduced by a factor defined by the parameter commondata::approach_conspecfic_dilute_general_risk (the integer expected number of predators is actually obtained by the floor intrinsic giving the lower integer value). (Therefore, the reduced expectancy is based on reduction of the expected number of predators while keeping memory part of the expectation fixed).
Expectation of the direct risk of predation depends on the target position of the actor agent 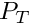 (with the target offset
(with the target offset 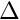 ) and relative distances between the actor agent, target conspecific
) and relative distances between the actor agent, target conspecific 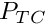 and all the predators
and all the predators 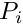 in the current perception object of the actor agent following the predicted agent movement.
in the current perception object of the actor agent following the predicted agent movement.
First, allocate the array risk_pred_expect that keeps the values of risk for each of the predators in the perception object.
Then, cycle over all the predators in the current perception object of the actor agent 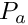 and check if the prospective movement towards the target conspecific would place the agent further from the predator (a) than the target conspecific:
and check if the prospective movement towards the target conspecific would place the agent further from the predator (a) than the target conspecific: 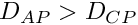 . If yes, direct risk of predation for this predator is equal to the risk of predation
. If yes, direct risk of predation for this predator is equal to the risk of predation 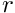 unadjusted for the dilution or confusion effects multiplied by the commondata::approach_conspecfic_adjust_pair_behind factor (normally 1/2 as diluted in a half by the target conspecific,
unadjusted for the dilution or confusion effects multiplied by the commondata::approach_conspecfic_adjust_pair_behind factor (normally 1/2 as diluted in a half by the target conspecific, 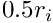 ). If the movement is likely to place the actor agent closer to the predator than the target conspecific
). If the movement is likely to place the actor agent closer to the predator than the target conspecific  , the expected risk for the actor agent is calculated as unadjusted value
, the expected risk for the actor agent is calculated as unadjusted value 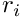 .
.
Thus, the predator dilution effect is introduced only if the actor agent is moving to the backward position further away from the predator (a) than the target conspecific (the target conspecific then is closer to the predator and suffers higher risk). If the actor agent moves to the forward position with respect to the predator (b), it suffers full unadjusted risk instead. This is the classical "selfish herd" effect.
Finally, the maximum value of the predation risks across all the predators 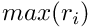 in the perception object of the actor agent constitutes the "final" expectation of the direct risk of predation: the_behaviour::approach_conspec::expected_pred_dir_risk.
in the perception object of the actor agent constitutes the "final" expectation of the direct risk of predation: the_behaviour::approach_conspec::expected_pred_dir_risk.
tmp_predator using the_environment::predator::make(). This predator's body size and the spatial position are obtained directly from the i-th predator 1/2 the agent's current perception object. But note that the agent is unable to determine the individually specific attack rate of the predator and uses the default value.tmp_predator) would become shorter than the distance between the target conspecific and the predator (i.e. the agent would go closer to the i-th predator than the target conspecific ), the direct risk of predation is calculated as unadjusted risk of predation computed using the the_environment::predator::risk_fish() method, assuming the actor agent is in the target approach position target_position_agent.), the baseline predation risk the_environment::predator::risk_fish() is diluted by a factor constant that is defined by the parameter commondata::approach_conspecfic_dilute_adjust_pair_behind (normally 1/2, i.e. diluted halfway by the target conspecific that is going to be closer to this predator).The expected food gain is assumed to be reduced due to possible competition if the agent approaches a conspecific. Furthermore, the competition effect should depend on the relative body masses of the actor agent and the target conspecific.
First, a baseline assessment of the food gain 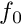 is calculated that does not take into account any effects of competition with the target conspecific. It is equal to the average mass of all food items in the current food perception object weighted by the subjective probability of food item capture that is calculated based on the memory the_neurobio::perception::food_probability_capture_subjective(). (The mass is zero if there are no food items perceived).
is calculated that does not take into account any effects of competition with the target conspecific. It is equal to the average mass of all food items in the current food perception object weighted by the subjective probability of food item capture that is calculated based on the memory the_neurobio::perception::food_probability_capture_subjective(). (The mass is zero if there are no food items perceived).
The expected value of the food gain when the agent is about to approach the target conspecific is calculated as the baseline expected food gain multiplied by a nonparametric weighting function that depends on the ratio of the body mass of the actor agent 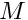 and the target conspecific
and the target conspecific 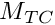 :
:
![\[ f = f_0 \Phi ( \frac{M}{M_{TC}} ) . \]](form_18.png)
The function  is defined by the grid set by the arrays commondata::approach_food_gain_compet_factor_abscissa and commondata::approach_food_gain_compet_factor_ordinate.
is defined by the grid set by the arrays commondata::approach_food_gain_compet_factor_abscissa and commondata::approach_food_gain_compet_factor_ordinate.
Interpolation plots can be saved in the debug mode using this plotting command: commondata::debug_interpolate_plot_save().
Definition at line 2622 of file m_behav.f90.
| subroutine the_behaviour::approach_conspecifics_motivations_expect | ( | class(approach_conspec), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| class(spatial), intent(in), optional | target_object, | ||
| real(srp), intent(in), optional | target_offset, | ||
| integer, intent(in), optional | time_step_model, | ||
| real(srp), intent(in), optional | rescale_max_motivation | ||
| ) |
the_behaviour::approach_conspec::expectancies_calculate() (re)calculates motivations from fake expected perceptions following from the procedure the_behaviour::approach_conspec::do_this().
| [in] | this_agent | this_agent is the actor agent which approaches a target conspecific. |
| [in] | target_object | target_object is the spatial target object the actor agent is going to approach. |
| [in] | target_offset | target_offset is an optional offset for the target, so that the target position of the approaching agent does not coincide with the target object. If absent, a default value set by the commondata::approach_offset_default is used. |
| [in] | time_step_model | time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
| [in] | rescale_max_motivation | rescale_max_motivation optional maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
The probability of capture of the expected food object.
Expected food gain that is fitting into the stomach of the agent.
A full list of all perception overrides is available in the description of the the_neurobio::percept_components_motiv::motivation_components() procedure.
perception_override_predator is the expected general predation risk, that is based on a weighting of the current predation and predation risk from the memory stack.
Check optional time step parameter. If not provided, use global parameter value from commondata::global_time_step_model_current.
Determine the target offset. Target offset target_offset can be provided as an optional dummy parameter to this procedure. However, if it is not provided explicitly, a default value is set as an average of the actor agent body length and the target conspecific body length. The the_neurobio::get_prop_size() method for polymorphic object gets the size of the target conspecific.
As the first step, we use the do-procedure approach_conspec::do_this() to perform the behaviour desired without changing either the agent or its environment, obtaining the subjective values of the this behaviour components that later feed into the motivation expectancy functions:
perception_override_food_dirperception_override_pred_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyFirst, create a fake food item with the spatial position identical to that of the agent. The position is used only to calculate the illumination and therefore visual range. The cost(s) are calculated providing explicit separate distance parameter, so the zero distance from the agent is inconsequential. The size of the food item is obtained from the expected food gain by the reverse calculation function the_environment::mass2size_food(). Standard make method for the food item class is used.
Second, calculate the probability of capture of this expected food item. The probability of capture of the fake food item is calculated using the the_environment::food_item::capture_probability() backend assuming the distance to the food item is equal to the average distance of all food items in the current perception object. However, if the agent does not see any food items currently, the distance to the fake food item is assumed to be equal to the visibility range weighted by the (fractional) commondata::walk_random_dist_expect_food_uncertain_fact parameter. Thus, the expected raw food gain (in the do-function) is based on the past memory whereas the probability of capture is based on the latest perception experience.
Third, the expected food gain corrected for fitting into the agent's current stomach (and subtracting capture cost) is obtained by the_body::condition::food_fitting(). It is then weighted by the expected capture probability. Note that the probability of capture (weighting factor) is calculated based on the current perception (see above), but the travel cost is based on the actual expected %distance (see the_behaviour::walk_random::expectancies_calculate() for a similar procedure).
Stomach content: the perception override value for the stomach content is obtained incrementing the current stomach contents by the nonzero expected food gain, adjusting also for the digestion decrement (the_body::stomach_emptify_backend()).
Body mass: the body mass perception override is obtained by incrementing (or decrementing if the expected food gain is negative) the current body mass by the expected food gain and also subtracting the cost of living component.
Energy: The fake perception values for the energy reserves (energy_override_perc) using the the_body::energy_reserve() procedure.
Direct food perception: override is based on the current count of the food items in the perception object.
Predation risk: finally, fake perceptions of predation risk are obtained from the values calculated in the do procedure: the_behaviour::approach_conspec::expected_pred_dir_risk and the_behaviour::approach_conspec::expected_predation_risk.
The next step is to calculate the motivational expectancies using the fake perceptions to override the default (actual agent's) values. At this stage, first, calculate motivation values resulting from the behaviour done (the_behaviour::approach_conspec::do_this()) at the previous steps:
Technically, this is done by calling the neuronal response function, percept_components_motiv::motivation_components() method, for each of the motivational states with perception_override_ dummy parameters overriding the default values. Here is the list of the fake overriding perceptions for the the_behaviour::approach_conspec behaviour:
perception_override_food_dirperception_override_pred_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyReal agent perception components are now substituted by the fake values resulting from executing this behaviour (approach::do_this() method). This is repeated for all the motivations: hunger, passive avoidance, fear state etc. These optional override parameters are substituted by the "fake" values.
Next, from the perceptual components calculated at the previous step we can obtain the primary and final motivation values by weighed summing.
Here we can use global maximum motivation across all behaviours and perceptual components if it is provided, for rescaling.
Or can rescale using local maximum value for this behaviour only.
Transfer attention weights from the actor agent this_agent to the this behaviour component. So, we will now use the updated modulated attention weights of the agent rather than their default parameter values.
So the primary motivation values are calculated.
Primary motivations are logged in the debug mode.
There is no modulation at this stage, so the final motivation values are the same as primary motivations.
Finally, calculate the finally expected arousal level for this behaviour. As in the GOS, the overall arousal is the maximum value among all motivation components.
Log also the final expectancy value in the debug mode.
Now as we know the expected arousal, we can choose the behaviour which would minimise this arousal level.
Definition at line 3109 of file m_behav.f90.
| elemental subroutine the_behaviour::migrate_init_zero | ( | class(migrate), intent(inout) | this | ) |
Initialise the migrate behaviour component to a zero state.
First init components from the base root class the_behaviour::behaviour_base. Mandatory label component that should be read-only.
The execution status is always FALSE, can be reset to TRUE only when the behaviour unit is called to execution.
And the expectancy components.
Abstract MOVE component.
Then init components of this specific behaviour component extended class.
Definition at line 3532 of file m_behav.f90.
| subroutine the_behaviour::migrate_do_this | ( | class(migrate), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| class(environment), intent(in) | target_env, | ||
| integer, intent(in), optional | predict_window_food, | ||
| integer, intent(in), optional | predict_window_consp, | ||
| integer, intent(in), optional | predict_window_pred, | ||
| integer, intent(in), optional | time_step_model | ||
| ) |
The "do" procedure component of the behaviour element performs the behaviour without affecting the actor agent (the_agent) and the world (here food_item_eaten) which have intent(in), so it only can change the internal representation of the behaviour (the type to which this procedure is bound to, here MIGRATE).
| [in] | this_agent | this_agent is the actor agent which eats the food item. |
| [in] | target_env | target_env the target environment the actor agent is going to (e)migrate into. |
| [in] | predict_window_food | predict_window_food optional size of the food prediction window, i.e. how many steps back in memory are used to calculate the predicted food gain. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | predict_window_consp | predict_window_consp optional size of the conspecifics prediction window, i.e. how many steps back in memory are used to calculate the predicted food gain. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | predict_window_pred | predict_window_pred optional size of the predator prediction window, i.e. how many steps back in memory are used to calculate the predicted food gain. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | time_step_model | time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
distance_target is the distance to the target environment
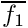 and "newer"
and "newer"  values of food availability retrieved from the perception memory. Used in calculation of the the_behaviour::hope function. and "newer" values of food availability retrieved from the perception memory. Used in calculation of the the_behaviour::hope function. and "newer" values of food availability retrieved from the perception memory. Used in calculation of the the_behaviour::hope function.
values of food availability retrieved from the perception memory. Used in calculation of the the_behaviour::hope function. and "newer" values of food availability retrieved from the perception memory. Used in calculation of the the_behaviour::hope function. and "newer" values of food availability retrieved from the perception memory. Used in calculation of the the_behaviour::hope function.Check optional parameter for the food perception memory window. If the predict_window_food dummy parameter is not provided, its default value is its default value is the whole memory stack commondata::history_size_perception.
Check optional parameter for the conspecifics perception memory window. If the predict_window_consp dummy parameter is not provided, its default value is the whole memory stack commondata::history_size_perception.
Check optional parameter for the general predation risk perception memory window. If the predict_window_pred dummy parameter is not provided, its default value is the whole memory stack commondata::history_size_perception.
Check optional time step parameter. If unset, use global commondata::global_time_step_model_current.
The distance towards the target environment (and the target point in this environment) is defined as the minimum distance towards all segments limiting this environment in the 2D X x Y projection
The target point for the migrating agent within the target environment is then not just the edge of the target environment, but some point penetrating inside to some distance defined by the parameter commondata::migrate_dist_penetrate_offset (in units of the agent's body length). The the_environment::environment::nearest_target() method is used to find the closest point in the target environment and the (smallest) distance towards this environment, these values are adjusted automatically for the offset parameter in the procedure call.
The distance value returned from the the_environment::environment::nearest_target() is saved into the this%distance data component and the target point (of class the_environment::spatial) is saved into the this%target_point data component.
Check if the distance to the target environment exceeds the migration travel maximum value, set as commondata::migrate_dist_max_step body sizes of the agent.
The expected cost of swimming in the random walk depends on the walk distance and is calculated using the the_body::condition::cost_swim() assuming laminar flow (laminar flow is due to normal relatively slow swimming pattern).
The expected food gain resulting from emigrating into a completely different novel habitat cannot be assessed based only on current perception because the agent has virtually no information (i.e. no perception) about this habitat yet. The target habitat is a novel environment about which the agent has absolutely no local knowledge. A mechanism based on the hope function (the_behaviour::hope()) is used here. Specifically, the hope function calculates the expected food gain in the target novel habitat based on the ratio of the "newer" to "older" food gains in the perceptual memory of the agent.
Calculation of the "older" and "newer" average food gain values from the memory involves several steps. First, average number of food items and the average size of the food items in the above two halves of the memory stack is calculated using the the_neurobio::memory_perceptual::get_food_mean_n_split() and the_neurobio::memory_perceptual::get_food_mean_size_split() procedures. (Note that the split_val parameter to this procedure is not provided so the default 1/2 split is used.)
Second, the values of the "old" and "new" food gain used to calculate the expectations are obtained by weighting the respective average mass of the food item by the average number of food items if this number is less than 1 or 1 (i.e. unweighted) if their average number is higher.
where  is the average mass of the food items and
is the average mass of the food items and 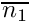 is the average number of food items in the "older" half of the perceptual memory stack and
is the average number of food items in the "older" half of the perceptual memory stack and 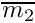 is the average mass of the food items and
is the average mass of the food items and 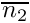 is the average number of food items in the "newer" half of the memory stack.
is the average number of food items in the "newer" half of the memory stack.
Thus, if the agent had some relatively poor perceptual history of encountering food items, so that the average number of food items is fractional < 1 (e.g. average number 0.5, meaning that it has seen a single food item approximately every other time step), the food gain is weighted by this fraction (0.5). If, on the other hand, the agent had more than one food items at each time step previously, the average food item size is unweighted (weight=1.0). This conditional weighting reflects the fact that it is not possible to eat more than one food item at a time in this model version.
The next step is to calculate the baseline food gain , against which the expectancy based on the the_behaviour::hope() function is evaluated. This baseline value is obtained by weighting the average mass of the food items in the whole memory stack 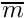 by their average number
by their average number 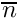 provided this number is n<1 as above:
provided this number is n<1 as above:
This baseline value is then weighted by the subjective probability of food item capture that is calculated based on the memory the_neurobio::perception::food_probability_capture_subjective().
Finally, the the_behaviour::hope() function is called with the above estimates for the baseline food gain, its "older" and "newer" values. The zero hope ratio and the maximum hope parameters are obtained from commondata::migrate_food_gain_ratio_zero_hope and commondata::migrate_food_gain_maximum_hope parameter constants.
A similar, although simpler, procedure based on the the_behaviour::hope function as above is used to calculate the expected number of food items perceived in the target novel habitat.
Here, the baseline value is the current number of food items in the food perception object, and the historical ratio  is calculated as the mean number of food items in the old to new memory parts:
is calculated as the mean number of food items in the old to new memory parts:
![\[ \varrho = \frac{\overline{n_2}}{\overline{n_1}} . \]](form_29.png)
The zero hope ratio and the maximum hope parameters are also obtained from commondata::migrate_food_gain_ratio_zero_hope and commondata::migrate_food_gain_maximum_hope parameter constants.
Direct predation risk is assumed to be zero for migration.
General predation risk expectancy is not possible to determine because there is no local perception of the target novel environment yet. Therefore, its assessment is based on the the_behaviour::hope() function, just as the expected food gain.
Second, calculate the current general risk of predation, based on the local perception. This is done calling the the_neurobio::predation_risk_backend() function. This current risk serves as a baseline value ( ) for calculation of the general risk in the target novel environment.
The expected number of conspecifics in the target environment is calculated as an average retrieved from the memory stack with the memory window defined by predict_window_consp_here.
Definition at line 3567 of file m_behav.f90.
| subroutine the_behaviour::migrate_motivations_expect | ( | class(migrate), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| class(environment), intent(in) | target_env, | ||
| integer, intent(in), optional | predict_window_food, | ||
| integer, intent(in), optional | predict_window_consp, | ||
| integer, intent(in), optional | predict_window_pred, | ||
| integer, intent(in), optional | time_step_model, | ||
| real(srp), intent(in), optional | rescale_max_motivation | ||
| ) |
the_behaviour::migrate::expectancies_calculate() (re)calculates motivations from fake expected perceptions following from the procedure migrate::do_this().
| [in] | this_agent | this_agent is the actor agent which is going to migrate. |
| [in] | target_env | target_env the target environment the actor agent is going to (e)migrate into. |
| [in] | predict_window_food | predict_window_food optional size of the food prediction window, i.e. how many steps back in memory are used to calculate the predicted food gain. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | predict_window_consp | predict_window_consp optional size of the conspecifics prediction window, i.e. how many steps back in memory are used to calculate the predicted food gain. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | predict_window_pred | predict_window_pred optional size of the predator prediction window, i.e. how many steps back in memory are used to calculate the predicted food gain. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | time_step_model | time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
| [in] | rescale_max_motivation | rescale_max_motivation optional maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
Expected food gain that is fitting into the stomach of the agent.
The probability of capture of the expected food object.
perception_override_pred_dir is the expected direct predation risk.
Check optional parameter for the food perception memory window. If the predict_window_food dummy parameter is not provided, its default value is its default value is the whole memory stack commondata::history_size_perception.
Check optional parameter for the conspecifics perception memory window. If the predict_window_consp dummy parameter is not provided, its default value is the whole memory stack commondata::history_size_perception.
Check optional parameter for the general predation risk perception memory window. If the predict_window_pred dummy parameter is not provided, its default value is the whole memory stack commondata::history_size_perception.
Check optional time step parameter. If unset, use global commondata::global_time_step_model_current.
As the first step, we use the do-procedure migrate::do_this() => the_behaviour::walk_random_do_this() to perform the behaviour desired without changing either the agent or its environment, obtaining the subjective values of the this behaviour components that later feed into the motivation expectancy functions:
perception_override_food_dirperception_override_conspecperception_override_pred_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyFirst, create a fake food item with the spatial position identical to that of the agent. The position is used to calculate the current illumination and therefore visual range. The cost(s) are calculated providing explicit separate distance parameter. The size of the food item is obtained from the expected food gain by the reverse calculation function the_environment::mass2size_food(). Standard make method for the food item class is used.
Second, calculate the probability of capture of this expected food item. The probability of capture of the fake food item is calculated using the the_environment::food_item::capture_probability() backend assuming the distance to the food item is equal to the average distance of all food items in the current perception object. However, if the agent does not see any food items currently, the distance to the fake food item is assumed to be equal to the visibility range weighted by the (fractional) commondata::dist_expect_food_uncertain_fact parameter.
Third, the expected food gain corrected for fitting into the agent's stomach and capture cost is obtained by the_body::condition::food_fitting(). It is then weighted by the expected capture probability.
Stomach content: the perception override value for the stomach content is obtained incrementing the current stomach contents by the nonzero expected food gain, adjusting also for the digestion decrement (the_body::stomach_emptify_backend()).
Body mass: the body mass perception override 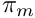 is obtained by incrementing (or decrementing if the expected food gain is negative) the current body mass by the expected food gain
is obtained by incrementing (or decrementing if the expected food gain is negative) the current body mass by the expected food gain 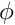 and also subtracting the cost of living
and also subtracting the cost of living 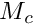 (the_body::condition::living_cost()) and the expected cost of movement into the target novel habitat
(the_body::condition::living_cost()) and the expected cost of movement into the target novel habitat 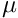 :
:
![\[ \pi_m = M + \phi - M_c - \mu \]](form_34.png)
Thus, probability of capture and costs of food processing in calculating the stomach content increment depend on the distance to the expected food item and do not take into account the travel cost to the novel environment (it can be quite large, beyond the visibility of the expected food item). However, expectancy of the body mass (the fake perception value) takes into account the cost of migration movement to the novel target habitat.
Energy: The fake perception values for the energy reserves (energy_override_perc) using the the_body::energy_reserve() procedure.
Direct food perception: The fake perception of the number of food items expected for the perception in the target novel environment is calculated from the this%expected_food_dir component (obtained in the do_this procedure).
Predation risk: fake perceptions of predation risk are obtained from the values calculated in the do procedure: the_behaviour::migrate::expected_pred_dir_risk and the_behaviour::migrate::expected_predation_risk.
Number of conspecifics: finally, the fake perception of the number of conspecifics is calculated from the values calculated in the do procedure: the_behaviour::migrate::expected_consp_number.
The next step is to calculate the motivational expectancies using the fake perceptions to override the default (actual agent's) values. At this stage, first, calculate motivation values resulting from the behaviour done (migrate::do_this() ) at the previous steps: what would be the motivation values if the agent does perform MIGRATE? Technically, this is done by calling the neuronal response function, percept_components_motiv::motivation_components() method, for each of the motivational states with perception_override_ dummy parameters overriding the default values. Here is the list of the fake overriding perceptions for the MIGRATE behaviour:
perception_override_food_dirperception_override_conspecperception_override_pred_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyReal agent perception components are now substituted by the fake values resulting from executing this behaviour (reproduce::do_this() => the_behaviour::reproduce_do_this() method). This is repeated for all the motivations: hunger, passive avoidance, active avoidance etc. These optional override parameters are substituted by the "fake" values.
Next, from the perceptual components calculated at the previous step we can obtain the primary and final motivation values by weighed summing.
Here we can use global maximum motivation across all behaviours and perceptual components if it is provided, for rescaling.
Or can rescale using local maximum value for this behaviour only.
Transfer attention weights from the actor agent this_agent to the this behaviour component. So, we will now use the updated modulated attention weights of the agent rather than their default parameter values.
So the primary motivation values are calculated.
Primary motivations are logged in the debug mode.
There is no modulation at this stage, so the final motivation values are the same as primary motivations.
Finally, calculate the finally expected arousal level for this behaviour. As in the GOS, the overall arousal is the maximum value among all motivation components.
Log also the final expectancy value in the debug mode.
Now as we know the expected arousal, we can choose the behaviour which would minimise this arousal level.
Definition at line 3992 of file m_behav.f90.
| subroutine the_behaviour::migrate_do_execute | ( | class(migrate), intent(inout) | this, |
| class(appraisal), intent(inout) | this_agent, | ||
| class(environment), intent(in) | target_env | ||
| ) |
Execute this behaviour component "migrate" by this_agent agent.
| [in,out] | this_agent | [in] this_agent is the actor agent which goes down. |
| [in] | target_env | target_env the target environment the actor agent is going to (e)migrate into. |
First, we use the intent-in do-procedure the_behaviour::migrate::do_this() to perform the behaviour desired. However, instead of expectations, get the target point in the novel habitat.(Expectancies for food gain, predator risk etc. are not used at this stage, memory windows are absent from the parameter list.)
The agent does a directional walk at this%distance towards the this%target_point in the novel target environment. However, it is possible only if the walk distance does not exceed the maximum value defined by the commondata::migrate_dist_max_step body sizes of the agent.
If the above limit on the length of a single walk is not exceeded, the agent relocates to the target point in the novel target environment. It is now in the target environment.
In the DEBUG Mode, print diagnostic information to the logger.
Additionally, also call the the_body::condition::set_length() method to update the body length history stack. However, the value_set parameter here is just the current value. This fake re-setting of the body length is done to keep both mass and length synchronised in their history stack arrays (there is no procedure for only updating history).
Finally, check if the agent is starved to death. If yes, the agent can die without going any further.
Random walk does not affect the environmental objects.
Definition at line 4467 of file m_behav.f90.
| pure real(srp) function the_behaviour::hope | ( | real(srp), intent(in) | baseline, |
| real(srp), intent(in) | memory_old, | ||
| real(srp), intent(in) | memory_new, | ||
| real(srp), intent(in), optional | zero_hope, | ||
| real(srp), intent(in), optional | maximum_hope, | ||
| real(srp), dimension(:), intent(in), optional | raw_grid_x, | ||
| real(srp), dimension(:), intent(in), optional | raw_grid_y | ||
| ) |
The hope function for the assessment of expectancy for a completely novel stimulus or environment for which local information is absent.
Calculation of the expectancy and therefore fake perceptions is not possible for completely novel environment or stimuli (e.g. for emigrating into a completely different novel habitat) based on the current perception because the agent has absolutely no local information (i.e. no perception of this habitat yet).
A mechanism based on the hope function should be used in such a case.
based on the locally available information (e.g. local expectation of the food gain) is selected.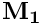 and newer
and newer 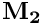 , and newer parts,
, and newer parts,
![\[ \varrho = \frac{\overline{f_2}}{\overline{f_1}} . \]](form_37.png)
Following this, the expectancy (e.g. expected food gain) for the novel stimuli or situation is calculated as:
![\[ F_{exp}= f_0 \cdot \Xi(\varrho) , \]](form_38.png)
where is the baseline food gain against which the expectancy is evaluated, and 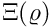 is the "hope" function that is obtained as a nonparametric relationship (see the right panel plots above): nonlinear interpolation based on the grid vectors
is the "hope" function that is obtained as a nonparametric relationship (see the right panel plots above): nonlinear interpolation based on the grid vectors  and
and  :
:
where  is the zero hope ratio parameter and
is the zero hope ratio parameter and 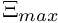 is the maximum hope parameter.
is the maximum hope parameter.
| [in] | baseline | baseline is the baseline stimulus expectancy that is based on the locally available information. |
| [in] | memory_old | memory_old is the older part (half) of the memory stack for the baseline perception. |
| [in] | memory_new | memory_new is the newer part (half) of the memory stack for the baseline perception. |
| [in] | zero_hope | zero_hope is the zero hope ratio parameter of the hope function grid abscissa vector. |
| [in] | maximum_hope | maximum_hope is the maximum hope parameter of the hope function grid ordinate vector. |
| [in] | raw_grid_x | raw_grid_x a raw interpolation grid array that can be provided (along with raw_grid_y) instead of the normal zero_hope and maximum_hope parameters. |
| [in] | raw_grid_y | raw_grid_y a raw interpolation grid array that can be provided (along with raw_grid_x) instead of the normal zero_hope and maximum_hope parameters. |
zero_hope and maximum_hope represent the normal standard way to provide the interpolation grid for the hope function. However, these grids can also be accepted as raw grid arrays (see raw_grid_x and raw_grid_y parameters below). zero_hope and maximum_hope are simultaneously provided. raw_grid_x and raw_grid_y must have the same length. hope_func_grid_abscissa and hope_func_grid_ordinate are the hope function grid arrays. They define the nonparametric hope function that is obtained by nonlinear interpolation. These arrays can be also provided as raw raw_grid_x raw_grid_y parameters.
First, calculate the memory-based ratio
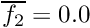 ; in such a case, the ratio is set to the maximum abscissa grid value resulting in zero hope function.
; in such a case, the ratio is set to the maximum abscissa grid value resulting in zero hope function.An additional case of both 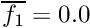 and is also checked, the ratio in such a case is set to 1.0, bringing about a unity hope function value (i.e. baseline expectancy is unchanged).
and is also checked, the ratio in such a case is set to 1.0, bringing about a unity hope function value (i.e. baseline expectancy is unchanged).
Second, get the hope function grid vectors and as:
V = [ 0.0_SRP, 1.00_SRP, zero_hope ] W = [ maximum_hope, 1.00_SRP, ZERO ]
Finally, the hope function value is obtained from a nonlinear interpolation based on DDPINTERPOL (see HEDTOOLS) with the interpolation grid defined by the (abscissa) and (ordinate) vectors.
If neither a pair of the scalar parameters zero_hope and maximum_hope nor the raw grid arrays raw_grid_x and raw_grid_y are provided, return commondata::missing value as an indicator of error.
Definition at line 4656 of file m_behav.f90.
| elemental real(srp) function the_behaviour::depth_walk_default | ( | real(srp), intent(in) | length, |
| real(srp), intent(in), optional | walk_factor | ||
| ) |
Calculate the default upward and downward walk step size. This function is called from the_behaviour::go_down_do_this() and the_behaviour::go_down_motivations_expect() if the upwards or downwards walk size is not provided explicitly.
| [in] | length | length The body length of the agent. |
| [in] | walk_factor | walk_factor The multiplocation factor for the walk step. The fdefault value is defined by the parameter commondata::up_down_walk_step_stdlength_factor. |
If the walk size is not provided, it is set equal to the agent's body length multiplied by the commondata::up_down_walk_step_stdlength_factor factor parameter.
Definition at line 4781 of file m_behav.f90.
| elemental subroutine the_behaviour::go_down_depth_init_zero | ( | class(go_down_depth), intent(inout) | this | ) |
Initialise the go down to a deeper spatial layer behaviour component to a zero state.
First init components from the base root class the_behaviour::behaviour_base. Mandatory label component that should be read-only.
The execution status is always FALSE, can be reset to TRUE only when the behaviour unit is called to execution.
And the expectancy components.
Abstract MOVE component.
Then init components of this specific behaviour component extended class.
Definition at line 4807 of file m_behav.f90.
| subroutine the_behaviour::go_down_do_this | ( | class(go_down_depth), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| real(srp), intent(in) | max_depth, | ||
| real(srp), intent(in), optional | depth_walk, | ||
| integer, intent(in), optional | predict_window_food, | ||
| integer, intent(in), optional | time_step_model | ||
| ) |
Do go down by this_agent (the actor agent). Subjective assessment of the motivational value for this is based on the number of food items, conspecifics and predators at the layers below the this_agent actor agent.
| [in,out] | this | [inout] this the object itself. |
| [in] | this_agent | this_agent is the actor agent which goes down. |
| [in] | max_depth | max_depth is the maximum limit on the depth. |
| [in] | depth_walk | depth_walk Optional downward walk size, by how deep the agent goes down. |
| [in] | predict_window_food | predict_window_food the size of the prediction window, i.e. how many steps back in memory are used to calculate the predicted food gain. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | time_step_model | time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
First, check if the size of the downward walk depth_walk dummy parameter is provided.
If it is not provided, it is set equal to the agent's body length multiplied by the commondata::up_down_walk_step_stdlength_factor factor parameter. Calculated by the_behaviour::depth_walk_default().
Check optional parameter for the food perception memory window. If the predict_window_food dummy parameter is not provided, its default value is the proportion of the whole perceptual memory window defined by commondata::history_perception_window_food. Thus, only the latest part of the memory is used for the prediction of the future food gain.
Check optional time step parameter. If unset, use global commondata::global_time_step_model_current.
Here, first, check if the target depth is likely to go beyond the environment depth limits and reduce the downward walk step size accordingly. Namely, if the depth coordinate of the actor agent plus the depth step exceeds the maximum depth, the step is reduced to be within the available environment: 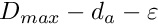 , where
, where 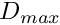 is the maximum depth,
is the maximum depth, 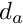 is the agent's current depth and
is the agent's current depth and 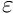 is a very small constant defined by the parameter commondata::zero.
is a very small constant defined by the parameter commondata::zero.
The down step size component of the class is then equal to the depth_walk.
The expected cost of the swimming down by the buoyancy is much smaller than active propulsion. It is set as a fraction, defined by the parameter commondata::swimming_cost_factor_buoyancy_down, of active laminar propulsion calculated by function the_body::condition_cost_swimming_burst().
Calculate the number of conspecifics at the down of the agent using the function perception::consp_below().
Calculate the expected predation risk at the down of the agent using the the_neurobio::predation_risk_backend() function. This is a general predation risk (the_neurobio::percept_components_motiv::predator), not direct risk based on the distance to the nearest predator (see the_neurobio::percept_components_motiv::pred_dir).
Calculate the expected food gain as an average mass of the food items down the agent. It is used by calling perception::food_mass_below() function. This expected food gain is then weighted by the subjective probability of food item capture that is calculated based on the memory the_neurobio::perception::food_probability_capture_subjective().
Definition at line 4838 of file m_behav.f90.
| subroutine the_behaviour::go_down_motivations_expect | ( | class(go_down_depth), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| real(srp), intent(in), optional | depth_walk, | ||
| real(srp), intent(in), optional | max_depth, | ||
| class(environment), dimension(:), intent(in), optional | environments, | ||
| integer, intent(in), optional | time_step_model, | ||
| real(srp), intent(in), optional | rescale_max_motivation | ||
| ) |
go_down_depth::motivations_expect() is a subroutine (re)calculating motivations from fake expected perceptions following from the procedure go_down_depth::do_this() => the_behaviour::go_down_do_this().
| [in,out] | this | [inout] this the object itself. |
| [in] | this_agent | this_agent is the actor agent which goes down. |
| [in] | depth_walk | depth_walk The downward walk size, by how deep the agent goes down. |
| [in] | max_depth | max_depth is the optional maximum limit on the depth. |
| [in] | environments | environments optional array of the all available environments where the this agent can be in, needed for the calculation of the depth limits. If such an array of the environments is provided, max_depth has precedence. |
| [in] | time_step_model | [in] time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
| [in] | rescale_max_motivation | rescale_max_motivation maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
Target depth, i.e. the absolute depth of the agent after it moves down.
expect_depth_perc_override is the fake perception of the depth, identical to the target depth.
Initially, check if the size of the downward walk depth_walk dummy parameter is provided.
If it is not provided, it is set equal to the agent's body length multiplied by the commondata::up_down_walk_step_stdlength_factor factor parameter. Calculated by the_behaviour::depth_walk_default().
Check downward step size. Here, first, check if the target depth is likely to go beyond the environment depth limits and reduce the downward walk step size accordingly. Either the explicitly provided maximum depth dummy parameter max_depth or an array of possible environment objects where the this_agent actor agent can be located is used to get the depth limit.
If the array of possible environment objects that can contain the actor agent is provided, the check involves the the_environment::spatial::find_environment() function to find the specific environment object the agent is currently in followed by the_environment::environment::depth_max() to find the minimum depth in this environment object.
If the array of possible environment objects that can contain the actor agent is not provided, the current environment is obtained from the global array the_environment::global_habitats_available. In this case, the environment that actor agent is within is determined using the the_environment::spatial::find_environment() method, which is in followed by the_environment::environment::depth_max()` to find the minimum depth in this environment object.
If max_depth is provided, it has precedence over the depth detected explicitly or implicitly from the environment objects.
In the case the maximum depth cannot be determined,it is set as the depth of the actor agent (with an additional condition that it should exceed zero), so movement down would be impossible.
If the depth coordinate of the actor agent plus the depth step exceeds the maximum depth, the step is reduced to be strictly within the available environment. However, it should also never be below zero.
Check optional time step parameter. If not provided, use global parameter value from commondata::global_time_step_model_current.
Assess the number of food items below using the perception::food_items_below() method.
Calculate the expected distance to the food item. It is equal to the average distance to the food items perceived below in case there are any such items perceived below. Calculated using the perception::food_dist_below() method.
However, if there are no food items below (resulting a commondata::missing distance, see perception::food_dist_below()), the expected distance is set the downward walk distance depth_walk, that should be sufficiently long to assure the probability of food item capture is very small or zero.
As the first step, we use the do-procedure go_down_depth::do_this() => the_behaviour::go_down_do_this() to perform the behaviour desired without changing either the agent or its environment, obtaining the subjective values of the this behaviour components that later feed into the motivation expectancy functions:
perception_override_lightperception_override_depthperception_override_food_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyThe absolute value of the target depth is equal to the agent's current depth plus the depth step class data component this%distance because the agent is intended to deepen down.
First, create a subjective representation of the expected food item that is used as a major reference for calculating fake override perceptions. First, calculate the fake coordinates for the expected food item, a spatial object of the class the_environment::spatial. They are equal to those of the actor agent, with the depth coordinate equal to the target depth.
Make an expected food item using the food_item standard method make (the_environment::food_item::make()) with the following parameters: the above spatial location, the size equal to the expected food gain from do_this, iid is set to commondata::unknown. Note that the size of the food item is reverse-calculated using the the_environment::mass2size_food() function.
Calculate the expected probability of capture (normally using the average distance to the food items under the agent perception::food_dist_below(), see above). Note that the illumination level in the calculation backend is set from the food item's current depth, i.e. the target depth of the agent. This means that the subjective illumination level used in the calculation of the capture probability is reduced automatically according to the agent's target depth.
Build the expected food gain perception. The mass increment that this_agent gets from consuming this food item is defined by the_body::condition::food_fitting.
the_body::condition::food_fitting already subtracts processing cost automatically. Note that the expected food increment is weighted by the expected probability of capture of the expected food item.Stomach increment from food is equal to the above value of the expected mass increment. However, stomach increment can only be zero or a positive value.
Finally, the fake perceptions for the body mass and stomach content are calculated as the current body mass minus the cost of moving to the target depth plus the expected food increment.
The expected fake perception value for the stomach content at the target depth is obtained similarly by adding the expected stomach increment to the current stomach content of the agent.
The expected energy reserves perceived are calculated from the fake perceptions of the mass and length using the_body::energy_reserve() function.
The fake perception value for the conspecifics at the target depth is calculated directly from the this class data component this%expected_consp_number.
The fake perception value for the predation risk at the target depth is calculated directly from the this class data component
The number of food items (direct food perception) is equal to the number of food items currently under the agent.
Depth perception is according to the absolute target depth value.
Light perception is according to the new depth.
The next step is to calculate the motivational expectancies using the fake perceptions to override the default (actual agent's) values. At this stage, first, calculate motivation values resulting from the behaviour done (go_down_depth::do_this()) at the previous steps: what would be the motivation values if the agent does perform GO_DOWN_DEPTH? Technically, this is done by calling the neuronal response function, percept_components_motiv::motivation_components() method, for each of the motivational states with perception_override_ dummy parameters overriding the default values. Here is the list of the fake overriding perceptions for the GO_DOWN_DEPTH behaviour:
perception_override_lightperception_override_depthperception_override_food_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyReal agent perception components are now substituted by the fake values resulting from executing this behaviour (reproduce::do_this() => the_behaviour::reproduce_do_this() method). This is repeated for all the motivations: hunger, passive avoidance, active avoidance etc. These optional override parameters are substituted by the "fake" values.
Next, from the perceptual components calculated at the previous step we can obtain the primary and final motivation values by weighed summing.
Here we can use global maximum motivation across all behaviours and perceptual components if it is provided, for rescaling.
Or can rescale using local maximum value for this behaviour only.
Transfer attention weights from the actor agent this_agent to the this behaviour component. So, we will now use the updated modulated attention weights of the agent rather than their default parameter values.
So the primary motivation values are calculated.
Primary motivations are logged in the debug mode.
There is no modulation at this stage, so the final motivation values are the same as primary motivations.
Finally, calculate the finally expected arousal level for this behaviour. As in the GOS, the overall arousal is the maximum value among all motivation components.
Log also the final expectancy value in the debug mode.
Now as we know the expected arousal, we can choose the behaviour which would minimise this arousal level.
Definition at line 4972 of file m_behav.f90.
| subroutine the_behaviour::go_down_do_execute | ( | class(go_down_depth), intent(inout) | this, |
| class(appraisal), intent(inout) | this_agent, | ||
| real(srp), intent(in), optional | max_depth, | ||
| class(environment), dimension(:), intent(in), optional | environments, | ||
| real(srp), intent(in), optional | depth_walk | ||
| ) |
Execute this behaviour component "go down" by this_agent agent.
| [in,out] | this | [inout] this the object itself. |
| [in,out] | this_agent | [in] this_agent is the actor agent which goes down. |
| [in] | max_depth | max_depth is the optional maximum limit on the depth. |
| [in] | environments | environments optional array of the all available environments where the this agent can be in, needed for the calculation of the depth limits. If such an array of the environments is provided, max_depth has precedence. |
| [in] | depth_walk | depth_walk Optional downward walk size, by how deep the agent goes down. |
First, check if the size of the downward walk depth_walk dummy parameter is provided.
If it is not provided, it is set equal to the agent's body length multiplied by the commondata::up_down_walk_step_stdlength_factor factor parameter. Calculated by the_behaviour::depth_walk_default().
Check downward step size. Here, first, check if the target depth is likely to go beyond the environment depth limits and reduce the downward walk step size accordingly. Either the explicitly provided maximum depth dummy parameter max_depth or an array of possible environment objects where the this_agent actor agent can be located is used to get the depth limit.
If the array of possible environment objects that can contain the max_depth actor agent is provided, the check involves the the_environment::spatial::find_environment() function to find the specific environment object the agent is currently in followed by the_environment::environment::depth_max() to find the minimum depth in this environment object.
If the array of possible environment objects that can contain the actor agent is not provided, the current environment is obtained from the global array the_environment::global_habitats_available. In this case, the environment that actor agent is within is determined using the the_environment::spatial::find_environment() method, which is in followed by the_environment::environment::depth_max()` to find the minimum depth in this environment object.
If max_depth is provided, it has precedence over the depth detected explicitly or implicitly from the environment objects.
In the case neither of the above optional parameters are provided, the maximum depth is set as the depth of the actor agent (with an additional condition that it should exceed zero), so movement down would be impossible.
First, we use the intent-in do-procedure go_down_depth::do_this() to perform the behaviour desired and get the expectations of fake perceptions for GOS. As a result, we now get this%decrement_mass_cost that defines the cost of buoyancy-based movement downwards.
Change the location of the actor agent, moving it down to the distance this%distance.
Decrement the body mass as a consequence of transfer down. This body mass decrement constitutes the (small) energetic cost of locomotion. Call the_body::condition::set_mass() for this.
Additionally, also call the the_body::condition::set_length() method to update the body length history stack. However, the value_set parameter here is just the current value. This fake re-setting of the body length is done to keep both mass and length synchronised in their history stack arrays (there is no procedure for only updating history).
After resetting the body mass, update energy reserves of the agent, that depend on both the length and the mass.
Check if the agent is starved to death. If yes, the agent can die without going any further.
Moving down by the agent does not affect the environmental objects.
Definition at line 5516 of file m_behav.f90.
| elemental subroutine the_behaviour::go_up_depth_init_zero | ( | class(go_up_depth), intent(inout) | this | ) |
Initialise the go up to a shallower spatial layer behaviour component to a zero state.
First init components from the base root class the_behaviour::behaviour_base. Mandatory label component that should be read-only.
The execution status is always FALSE, can be reset to TRUE only when the behaviour unit is called to execution.
And the expectancy components.
Abstract MOVE component.
Then init components of this specific behaviour component extended class.
Definition at line 5645 of file m_behav.f90.
| subroutine the_behaviour::go_up_do_this | ( | class(go_up_depth), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| real(srp), intent(in) | min_depth, | ||
| real(srp), intent(in), optional | depth_walk, | ||
| integer, intent(in), optional | predict_window_food, | ||
| integer, intent(in), optional | time_step_model | ||
| ) |
Do go up by this_agent (the actor agent). Subjective assessment of the motivational value for this is based on the number of food items, conspecifics and predators at the layers below the this_agent actor agent.
| [in,out] | this | [inout] this the object itself. |
| [in] | this_agent | this_agent is the actor agent which goes up. |
| [in] | min_depth | min_depth is the maximum limit on the depth. |
| [in] | depth_walk | depth_walk Optional downward walk size, by how deep the agent goes down. |
| [in] | predict_window_food | predict_window_food the size of the prediction window, i.e. how many steps back in memory are used to calculate the predicted food gain. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | time_step_model | time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
First, check if the size of the upward walk depth_walk dummy parameter is provided.
If it is not provided, it is set equal to the agent's body length multiplied by the commondata::up_down_walk_step_stdlength_factor factor parameter. Calculated by the_behaviour::depth_walk_default().
Check optional parameter for the food perception memory window. If the predict_window_food dummy parameter is not provided, its default value is the proportion of the whole perceptual memory window defined by commondata::history_perception_window_food. Thus, only the latest part of the memory is used for the prediction of the future food gain.
Check optional time step parameter. If unset, use global commondata::global_time_step_model_current.
Here, first, check if the target depth is likely to go beyond the environment depth limits and reduce the upwnward walk step size accordingly. Namely, if the depth coordinate of the actor agent minus the depth step exceeds the minimum depth, the step is reduced to be within the available environment: 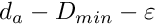 , where
, where 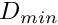 is the maximum depth, is the agent's current depth and is a very small constant defined by the parameter commondata::zero.
is the maximum depth, is the agent's current depth and is a very small constant defined by the parameter commondata::zero.
The upward step size component of the class is then equal to the depth_walk.
The expected cost of the swimming up by the buoyancy is much smaller than active propulsion. It is set as a fraction, defined by the parameter commondata::swimming_cost_factor_buoyancy_down, of active laminar propulsion calculated by function the_body::condition_cost_swimming_burst().
Calculate the number of conspecifics upwards of the agent using the function perception::consp_below().
Calculate the expected predation risk above the agent.
Calculate the expected food gain as an average mass of the food items above the agent. It is used by calling perception::food_mass_below() function. This expected food gain is then weighted by the subjective probability of food item capture that is calculated based on the memory the_neurobio::perception::food_probability_capture_subjective().
Definition at line 5676 of file m_behav.f90.
| subroutine the_behaviour::go_up_motivations_expect | ( | class(go_up_depth), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| real(srp), intent(in), optional | depth_walk, | ||
| real(srp), intent(in), optional | min_depth, | ||
| class(environment), dimension(:), intent(in), optional | environments, | ||
| integer, intent(in), optional | time_step_model, | ||
| real(srp), intent(in), optional | rescale_max_motivation | ||
| ) |
go_up_depth::motivations_expect() is a subroutine (re)calculating motivations from fake expected perceptions following from the procedure go_up_depth::do_this() => the_behaviour::go_up_do_this().
| [in,out] | this | [inout] this the object itself. |
| [in] | this_agent | this_agent is the actor agent which goes up. |
| [in] | depth_walk | depth_walk The upward walk size, by how deep the agent goes up. |
| [in] | min_depth | min_depth is the optional maximum limit on the depth. |
| [in] | environments | environments optional array of the all available environments where the this agent can be in, needed for the calculation of the depth limits. If such an array of the environments is provided, min_depth` has precedence. |
| [in] | time_step_model | [in] time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
| [in] | rescale_max_motivation | rescale_max_motivation maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
Target depth, i.e. the absolute depth of the agent after it moves up.
expect_depth_perc_override is the fake perception of the depth, identical to the target depth.
Initially, check if the size of the upward walk depth_walk dummy parameter is provided.
If it is not provided, it is set equal to the agent's body length multiplied by the commondata::up_down_walk_step_stdlength_factor factor parameter.Calculated by the_behaviour::depth_walk_default().
Check upward step size. Here, first, check if the target depth is likely to go beyond the environment depth limits and reduce the upward walk step size accordingly. Either the explicitly provided minimum depth dummy parameter min_depth or an array of possible environment objects where the this_agent actor agent can be located is used to get the depth limit.
If the array of possible environment objects that can contain the actor agent is provided, the check involves the the_environment::spatial::find_environment() function to find the specific environment object the agent is currently in followed by the_environment::environment::depth_min() to find the minimum depth in this environment object.
If the array of possible environment objects that can contain the actor agent is not provided, the current environment is obtained from the global array the_environment::global_habitats_available. In this case, the environment that actor agent is within is determined using the the_environment::spatial::find_environment() method, which is in followed by the_environment::environment::depth_max()` to find the minimum depth in this environment object.
If min_depth is provided, it has precedence over the depth detected from environment objects.
In the case the minimum depth cannot be determined,it is set as the depth of the actor agent (with an additional condition that it should exceed zero), so movement up would be impossible. Notably, it is not set to zero, a logical choice, to avoid possible asymmetric effects as the counterpart "move down" procedures use the agent's current depth as a last resort in the analogous case of no depth parameters.
If the depth coordinate of the actor agent minus the depth step is smaller than the minimum depth, the step is reduced to be strictly within the available environment. However, it should also never be below zero.
Check optional time step parameter. If not provided, use global parameter value from commondata::global_time_step_model_current.
Assess the number of food items above using the perception::food_items_above() method.
Calculate the expected distance to the food item. It is equal to the average distance to the food items perceived above in case there are any such items perceived above. Calculated using the perception::food_dist_above() method.
However, if there are no food items above (resulting a commondata::missing distance, see perception::food_dist_below()), the expected distance is set the upward walk distance depth_walk, that should be sufficiently long to assure the probability of food item capture is very small or zero.min_depth
As the first step, we use the do-procedure go_up_depth::do_this() => the_behaviour::go_up_do_this() to perform the behaviour desired without changing either the agent or its environment, obtaining the subjective values of the this behaviour components that later feed into the motivation expectancy functions:
perception_override_lightperception_override_depthperception_override_food_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyThe absolute value of the target depth is equal to the agent's current depth minus the depth step class data component this%distance because the agent is intended to lift up.
First, create a subjective representation of the expected food item that is used as a major reference for calculating fake override perceptions. First, calculate the fake coordinates for the expected food item, a spatial object of the class the_environment::spatial. They are equal to those of the actor agent, with the depth coordinate equal to the target depth.
Make an expected food item using the food_item standard method make (the_environment::food_item::make()) with the following parameters: the above spatial location, the size equal to the expected food gain from do_this, iid is set to commondata::unknown. Note that the size of the food item is reverse-calculated using the the_environment::mass2size_food() function.
Calculate the expected probability of capture (normally using the average distance to the food items above the agent perception::food_dist_above()). Note that the illumination level in the calculation backend is set from the food item's current depth, i.e. the target depth of the agent. This means that the subjective illumination level used in the calculation of the capture probability is increased automatically according to the agent's target depth.
Build the expected food gain perception. The mass increment that this_agent gets from consuming this food item is defined by the_body::condition::food_fitting.
the_body::condition::food_fitting already subtracts processing cost automatically. Note that the expected food increment is weighted by the expected probability of capture of the expected food item.Stomach increment from food is equal to the above value of the expected mass increment. However, stomach increment can only be zero or a positive value.
Finally, the fake perceptions for the body mass and stomach content are calculated as the current body mass minus the cost of moving to the target depth plus the expected food increment.
The expected fake perception value for the stomach content at the target depth is obtained similarly by adding the expected stomach increment to the current stomach content of the agent.
The expected energy reserves perceived are calculated from the fake perceptions of the mass and length using the_body::energy_reserve() function.
The fake perception value for the conspecifics at the target depth is calculated directly from the this class data component this%expected_consp_number.
The fake perception value for the predation risk at the target depth is calculated directly from the this class data component
The number of food items (direct food perception) is equal to the number of food items currently above the agent.
Depth perception is according to the absolute target depth value.
Light perception is according to the new depth.
The next step is to calculate the motivational expectancies using the fake perceptions to override the default (actual agent's) values. At this stage, first, calculate motivation values resulting from the behaviour done (go_up_depth::do_this()) at the previous steps: what would be the motivation values if the agent does perform GO_UP_DEPTH? Technically, this is done by calling the neuronal response function, percept_components_motiv::motivation_components() method, for each of the motivational states with perception_override_ dummy parameters overriding the default values. Here is the list of the fake overriding perceptions for the GO_UP_DEPTH behaviour:
perception_override_lightperception_override_depthperception_override_food_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyReal agent perception components are now substituted by the fake values resulting from executing this behaviour (reproduce::do_this() => the_behaviour::reproduce_do_this() method). This is repeated for all the motivations: hunger, passive avoidance, active avoidance etc. These optional override parameters are substituted by the "fake" values.
Next, from the perceptual components calculated at the previous step we can obtain the primary and final motivation values by weighed summing.
Here we can use global maximum motivation across all behaviours and perceptual components if it is provided, for rescaling.
Or can rescale using local maximum value for this behaviour only.
Transfer attention weights from the actor agent this_agent to the this behaviour component. So, we will now use the updated modulated attention weights of the agent rather than their default parameter values.
So the primary motivation values are calculated.
Primary motivations are logged in the debug mode.
There is no modulation at this stage, so the final motivation values are the same as primary motivations.
Finally, calculate the finally expected arousal level for this behaviour. As in the GOS, the overall arousal is the maximum value among all motivation components.
Log also the final expectancy value in the debug mode.
Now as we know the expected arousal, we can choose the behaviour which would minimise this arousal level.
Definition at line 5806 of file m_behav.f90.
| subroutine the_behaviour::go_up_do_execute | ( | class(go_up_depth), intent(inout) | this, |
| class(appraisal), intent(inout) | this_agent, | ||
| real(srp), intent(in), optional | min_depth, | ||
| class(environment), dimension(:), intent(in), optional | environments, | ||
| real(srp), intent(in), optional | depth_walk | ||
| ) |
Execute this behaviour component "go up" by this_agent agent towards.
| [in,out] | this | [inout] this the object itself. |
| [in,out] | this_agent | [in] this_agent is the actor agent which goes up. |
| [in] | min_depth | min_depth is the optional minimum limit on the depth. |
| [in] | environments | environments optional array of the all available environments where the this agent can be in, needed for the calculation of the depth limits. If such an array of the environments is provided, min_depth has precedence. |
| [in] | depth_walk | depth_walk Optional upward walk size, by how deep the agent goes up. |
First, check if the size of the upward walk depth_walk dummy parameter is provided.
If it is not provided, it is set equal to the agent's body length multiplied by the commondata::up_down_walk_step_stdlength_factor factor parameter. Calculated by the_behaviour::depth_walk_default().
Check upward step size. Here, first, check if the target depth is likely to go beyond the environment depth limits and reduce the upward walk step size accordingly. Either the explicitly provided minimum depth dummy parameter min_depth or an array of possible environment objects where the this_agent actor agent can be located is used to get the depth limit.
If the array of possible environment objects that can contain the actor agent is provided, the check involves the the_environment::spatial::find_environment() function to find the specific environment object the agent is currently in followed by in this the_environment::environment::depth_min() to find the minimum depth in this environment object.
If the array of possible environment objects that can contain the actor agent is not provided, the current environment is obtained from the global array the_environment::global_habitats_available. In this case, the environment that actor agent is within is determined using the the_environment::spatial::find_environment() method, which is in followed by the_environment::environment::depth_max()` to find the minimum depth in this environment object.
If min_depth is provided, it has precedence over the depth detected explicitly or implicitly from the environment objects.
In the case neither of the above optional parameters are provided, the minimum depth is set as the depth of the actor agent (with an additional condition that it should exceed zero), so movement up would be impossible. Notably, it is not set to zero, a logical choice, to avoid possible asymmetric effects as the counterpart "move down" procedures use the agent's current depth as a last resort in the analogous case of no depth parameters.
First, we use the intent-in do-procedure go_up_depth::do_this() to perform the behaviour desired and get the expectations of fake perceptions for GOS. As a result, we now get this%decrement_mass_cost that defines the cost of buoyancy-based movement upwards.
Change the location of the actor agent, moving it up to the distance this%distance.
Decrement the body mass as a consequence of transfer upwards. This body mass decrement constitutes the (small) energetic cost of locomotion. Call the_body::condition::set_mass() for this.
Additionally, also call the the_body::condition::set_length() method to update the body length history stack. However, the value_set parameter here is just the current value. This fake re-setting of the body length is done to keep both mass and length synchronised in their history stack arrays (there is no procedure for only updating history).
After resetting the body mass, update energy reserves of the agent, that depend on both the length and the mass.
Check if the agent is starved to death. If yes, the agent can die without going any further.
Moving down by the agent does not affect the environmental objects.
Definition at line 6351 of file m_behav.f90.
| elemental subroutine the_behaviour::debug_base_init_zero | ( | class(debug_base), intent(inout) | this | ) |
Initialise the fake debug behaviour behaviour component to a zero state.
First init components from the base root class the_neurobio::behaviour_base. Mandatory label component that should be read-only.
The execution status is always FALSE, can be reset to TRUE only when the behaviour unit is called to execution.
And the expectancy components.
Definition at line 6483 of file m_behav.f90.
| subroutine the_behaviour::debug_base_motivations_expect | ( | class(debug_base), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| integer, intent(in), optional | time_step_model, | ||
| real(srp), intent(in), optional | rescale_max_motivation | ||
| ) |
the_behaviour::debug_base::motivations_expect() is a subroutine (re)calculating motivations from fake expected perceptions for the fake debug behaviour.
| [in,out] | this | [inout] this the self object. |
| [in] | this_agent | this_agent is the actor agent which does reproduce. |
| [in] | time_step_model | [in] time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
| [in] | rescale_max_motivation | rescale_max_motivation maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
Check optional time step parameter. If not provided, use global parameter value from commondata::global_time_step_model_current.
This is the fake debug behaviour, for which the do-procedure is absent.
The motivation values resulting from the behaviour are calculated for unchanged perceptions. That is, no fake perceptions are placed into the percept_components_motiv::motivation_components() procedures.
From the perceptual components calculated at the previous step we can obtain the primary and final motivation values by weighed summing.
Here we can use global maximum motivation across all behaviours and perceptual components if it is provided, for rescaling.
Or can rescale using local maximum value for this behaviour only.
Transfer attention weights from the actor agent this_agent to the this behaviour component. So, we will now use the updated modulated attention weights of the agent rather than their default parameter values.
So the primary motivation values are calculated.
Primary motivations are logged in the debug mode.
There is no modulation at this stage, so the final motivation values are the same as primary motivations. TODO: Should include developmental or other modulation? If yes, need to separate genetic modulation component from motivation_modulation_genetic into a procedure bound to MOTIVATIONS with this_agent as actor.
Fourth, Calculate the finally expected arousal level for this behaviour. As in the GOS, the overall arousal is the maximum value among all motivation components.
Log also the final expectancy value in the debug mode.
Now as we know the expected arousal, we can choose the behaviour which would minimise this arousal level.
Definition at line 6505 of file m_behav.f90.
| subroutine the_behaviour::eat_food_item_do_this | ( | class(eat_food), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| class(food_item), intent(in) | food_item_eaten, | ||
| integer, intent(in), optional | time_step_model, | ||
| real(srp), intent(in), optional | distance_food_item, | ||
| real(srp), intent(in), optional | capture_prob, | ||
| logical, intent(out), optional | is_captured | ||
| ) |
Eat a food item defined by the object food_item_eaten. The "do" procedure component of the behaviour element performs the behaviour without affecting the actor agent (the_agent) and the world (here food_item_eaten) which have intent(in), so it only can change the internal representation of the behaviour (the type to which this procedure is bound to, here the_behaviour::eat_food). So, here the result of this procedure is assessment of the stomach content increment and body mass increment that would result from eating the this food item by the this_agent. The main output from this do procedure is the this behavioural unit, namely two of its internal data components:
distance_food_item, capture_prob, time_step_model. If they are not set, true objective values are calculated or used, e.g. time step of the model is taken from commondata::global_time_step_model_current and the distance between the agent and the food item distance_food_item is calculated from their spatial data. | [in,out] | this | [inout] this the object itself. |
| [in] | this_agent | this_agent is the actor agent which eats the food item. |
| [in] | food_item_eaten | food_item_eaten is the food object that is eaten. |
| [in] | time_step_model | time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
| [in] | distance_food_item | distance_food_item is the optional distance to the food item. |
| [in] | capture_prob | capture_prob is optional probability of capture of this food item, overrides the value calculated from the spatial data. |
| [out] | is_captured | is_captured optional capture flag, TRUE if the food item is captured by the agent. |
This food item, if found in the perception object, should be available. If not, something wrong has occurred. We cannot process an food item that has been already eaten, so no increments are done and error is reported into the log.
Check optional time step parameter.
Check distance to the food item. If provided, use the override value, if not, calculate from the the agent and the food item spatial data.
Check if food item capture probability is supplied.
If the food item capture probability is not supplied, calculate it based on the current distance between the predator agent and this food item. (commondata::food_item_capture_probability is a baseline value at near-zero distance).
The probability that the food item is captured is stochastic and is normally below 100%. However while calculating the behaviour expectancies, the capture probability is set to 1.0 to make the internal subjective processing deterministic. Stochastic capture success is now determined by the the_environment::food_item::capture_success() function.
distance_food_item_here is used here not only to calculate the probability of food item capture (above), but also the fast burst swimming cost of approaching the food item that is about to be eaten.The food item is captured, set the optional logical flag first.
The mass increment that this_agent gets from consuming this food item is defined by the_body::condition::food_fitting.
the_body::condition::food_fitting already subtracts processing cost.The food item is not captured, set the optional logical flag first.
If the food item is not captured, the agent has only to pay the energetic processing cost without food gain. The cost (mass decrement) is defined by the_body::condition::food_process_cost(). The stomach contents mass does not change in this case.
Definition at line 6725 of file m_behav.f90.
| subroutine the_behaviour::eat_food_item_motivations_expect | ( | class(eat_food), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| class(food_item), intent(in) | food_item_eaten, | ||
| integer, intent(in), optional | time_step_model, | ||
| real(srp), intent(in), optional | distance_food_item, | ||
| real(srp), intent(in), optional | capture_prob, | ||
| real(srp), intent(in), optional | rescale_max_motivation | ||
| ) |
eat_food::motivations_expect() is a subroutine (re)calculating motivations from fake expected perceptions following from the procedure eat_food::do_this() => the_behaviour::eat_food_item_do_this().
| [in,out] | this | [inout] this the self object. |
| [in] | this_agent | this_agent is the actor agent which does eat. |
| [in] | food_item_eaten | food_item_eaten is the food item object that is eaten. |
| [in] | time_step_model | [in] time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
| [in] | distance_food_item | distance_food_item optional distance to the food item, overrides the value calculated from the spatial data. |
| [in] | capture_prob | capture_prob is optional probability of capture of this food item, overrides the value calculated from the spatial data. |
| [in] | rescale_max_motivation | rescale_max_motivation maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
FOOD_CAPTURE_PROB is the expected (subjective) food item capture probability parameter. We assume that the agent assumes 100% probability of capture of the food item.
stomach_increment_from_food_perc is expected increment of the stomach contents that is used in the fake perception value in the neuronal response function.
stomach_overrride_perc is the fake perception value for the stomach contents that goes into the neuronal response function.
mass_increment_from_food_perc is the expected increment of the agent's body mass that is used in the fake perception value in the neuronal response function.
bodymass_override_perc is the fake perception value for the body mass that goes into the neuronal response function.
energy_override_perc is the fake perception value that goes into the neuronal response function.
capture_prob_intrinsic is the intrinsic probability of capture of the this food item. It is calculated using the food_item::capture_probability() method.
Check optional time step parameter. If not provided, use global parameter value from commondata::global_time_step_model_current.
Check distance to the food item. If provided, use the override value, if not, calculate from the the agent and the food item spatial data.
Check if food item capture probability is supplied. If capture probability is supplied as a dummy parameter to this procedure, it will override the intrinsic capture probability that is based on the distance between the predator agent and the food item it is about to eat. This may be for example necessary when a subjective expected motivational expectancy is calculated, it can assume 100% probability and/or weightings of the resulting motivation value(s).
If the food item capture probability is not supplied, expectancy is based on a 100% capture probability.
eat_food::do_this() procedure where the capture probability is calculated from the true objective values, the subjective expectancies are based by default on 100% expected probability of this food item capture.The intrinsic (objective) probability of capture of this food item capture_prob_intrinsic is calculated using the food_item::capture_probability() method.
First, we use the do-procedure eat_food::do_this() => the_behaviour::eat_food_item_do_this() to perform the behaviour desired without changing either the agent or its environment and here find representation values that later feed into the motivation expectancy functions.
time_step_model is not used here for calculating the capture probability because a fixed fake value of the later FOOD_CAPTURE_PROB is used.We then weight the subjective increments of the body mass and stomach content that are expected from eating this food item by the intrinsic objective capture probability capture_prob_intrinsic calculated for the current time step on the basis of the distance between the agent and the food item.
After this, it is possible to calculate the fake perceptions for the stomach contents (stomach_overrride_perc), body mass (bodymass_override_perc) and the energy reserves (energy_override_perc). These values are ready to be passed to the neuronal response function.
Second, we calculate motivation values resulting from the behaviour done (eat_food::do_this()) at the previous step: what would be the motivation values if the agent eats this food item? This is done by calling the neuronal response function, percept_components_motiv::motivation_components() method, for each of the motivational states with perception_override_ dummy parameters overriding the default values:
perception_override_stomach;perception_override_bodymass;perception_override_energy.Real agent perception components are now substituted by the fake values resulting from executing this behaviour (eat_food::do_this() => the_behaviour::eat_food_item_do_this() method). This is repeated for all the motivatios: hunger, passive avoidance, active avoidance etc. These optional override parameters are substituted by the "fake" values:
perception_override_stomach;perception_override_bodymass;perception_override_energy.Third, From the perceptual components calculated at the previous step we can obtain the primary and final motivation values by weighed summing.
Here we can use global maximum motivation across all behaviours and perceptual components if it is provided, for rescaling.
Or can rescale using local maximum value for this behaviour only.
Transfer attention weights from the actor agent this_agent to the this behaviour component. So, we will now use the updated modulated attention weights of the agent rather than their default parameter values.
So the primary motivation values are calculated.
Primary motivations are logged in the debug mode.
There is no modulation at this stage, so the final motivation values are the same as primary motivations. TODO: Should include developmental or other modulation? If yes, need to separate genetic modulation component from motivation_modulation_genetic into a procedure bound to MOTIVATIONS with this_agent as actor.
Fourth, Calculate the finally expected arousal level for this behaviour. As in the GOS, the overall arousal is the maximum value among all motivation components.
Log also the final expectancy value in the debug mode.
Now as we know the expected arousal, we can choose the behaviour which would minimise this arousal level.
Definition at line 6847 of file m_behav.f90.
| subroutine the_behaviour::eat_food_item_do_execute | ( | class(eat_food), intent(inout) | this, |
| class(appraisal), intent(inout) | this_agent, | ||
| class(food_item), intent(inout) | food_item_eaten, | ||
| class(food_resource), intent(inout) | food_resource_real, | ||
| logical, intent(out), optional | eat_is_success | ||
| ) |
Execute this behaviour component "eat food item" by this_agent agent towards the food_item_eaten.
| [in,out] | this | [inout] this the self object. |
| [in,out] | this_agent | [inout] this_agent is the actor agent which eats the food item. |
| [in,out] | food_item_eaten | [inout] food_item_eaten is the food item object that is eaten. |
| [in,out] | food_resource_real | [inout] food_resource_real The food resource we are eating the food item in. |
see_food method) because the food perception object contains copies of food items from the physical resource. So we have to change the availability status of the real physical resource items, not just items in the perception object of the agent. | [out] | eat_is_success | eat_is_success logical indicator showing if the food item has actually been eaten (TRUE) or failed (FALSE). |
First, check if this food item is not eaten and this agent is not dead. It should normally the case. If not, may point to a bug.
Now process the food item by this_agent.
First, we use the intent-in do-procedure eat_food::do_this() => the_behaviour::eat_food_item_do_this() to perform the behaviour desired and get the expectations of fake perceptions for GOS. As a result, we get mass_increment_from_food and stomach_increment_from_food.
this behaviour changes, and it will be later passed to modify the agent. capture_prob is not set here, so it is set to the true objective value that depends on the distance between the predator agent and the food item, see capture_probability function bound to the FOOD_ITEM class.Also, here set the optional output argument eat_is_success from the stochastic result (success/failed) of the foor item capture.
Also log the fake perceptions along with the agent's sex if running in the DEBUG mode.
Second, change the agent's state as a consequence of eating. (1) Grow the body length of the agent based on the mass increment from food.
(2). Grow the body mass of the agent.
mass_increment_from_food already has the processing cost subtracted. Specifically, the mass increment can be negative if the agent did not catch the food item. is_captured is False, we do call the mass and stomach increment procedures as in such a case there is a mass cost that is still subtracted (increment negative), and stomach increment is zero.(3). And increment the stomach contents of the agent using condition::stomach_increment().
(4). Update the energy reserves using the new currently updated mass and length by calling condition::energy_update().
(5). Check if the agent is starved to death. If yes, the agent can die without going any further.
Third, change the state of the environment. Disable the food item if it is eaten and not available any more. If the capture success if False, the item is not affected.
Set the eaten status to the food item in the perception object.
We also have to set the food item in the real food resource the same eaten/absent status because the perception object may operate on a copy of the real food objects. So we here first get the ID number of the food item.
Second, set the food item in the food resource with the same iid the absent/eaten status.
Log the food item eaten in the debug mode.
Definition at line 7248 of file m_behav.f90.
| elemental subroutine the_behaviour::reproduce_init_zero | ( | class(reproduce), intent(inout) | this | ) |
Initialise reproduce behaviour object.
First init components from the base root class the_behaviour::behaviour_base: Mandatory label component that should be read-only.
The execution status is always FALSE, can be reset to TRUE only when the behaviour unit is called to execution.
And the expectancy type components.
And init the expected arousal data component.
Second, init components of this specific behaviour (REPRODUCE) component extended class.
Definition at line 7450 of file m_behav.f90.
| integer function the_behaviour::maximum_n_reproductions | ( | class(appraisal), intent(in) | this | ) |
Calculate the maximum number of possible reproductions for this agent. It is assumed that a male can potentially fertilise several females that are within its perception object (in proximity) during a single reproduction event. For females, this number if always one.
Initialise the number of same- and opposite-sex conspecifics (integer counters) to zero.
First, determine if there are any conspecifics in the perception, if there are no, reproduction is impossible. Return straight away with zero result in such a case.
Second, check if this agent is female. If yes, only one fertilisation is possible, so return max_num=1.
Exit from the procedure afterwards.
From now on, it is assumed the agent is male. Third, determine how many conspecific male agents in the perception object have testosterone level higher than this actor agent. These conspecific male agents can take part in the fertilisation. However, all male conspecifics with testosterone lower than in this agent are out-competed by this agent and the other high-testosterone males and would not be involved in reproduction.
Finally, calculate the expected number of fertilised females, i.e. the number of reproductions for this agent assuming only this agent and all other male agents with the testosterone levels exceeding that in this agent can reproduce.
Definition at line 7485 of file m_behav.f90.
| subroutine the_behaviour::reproduce_do_this | ( | class(reproduce), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| real(srp), intent(in), optional | p_reproduction, | ||
| logical, intent(out), optional | is_reproduce | ||
| ) |
Do reproduce by this_agent (the actor agent) given the specific probability of successful reproduction. The probability of reproduction depends on the number of agents of the same and of the opposite sex within the visual range of the this agent weighted by the difference in the body mass between the actor agent and the average body mass of the other same-sex agents. The main output from this do procedure is the this behavioural unit object, namely its two components:
| [in,out] | this | [inout] this the object itself. |
| [in] | this_agent | this_agent is the actor agent which does/does not reproduce. |
| [in] | p_reproduction | p_reproduction optional probability of reproduction, overrides the value calculated from this_agent data. |
| [out] | is_reproduce | is_reproduce optional reproduction success flag, TRUE if the reproduction is successfully done by the agent. |
Determine if the agent's hormonal system is ready for reproduction, that its current level of sex steroids 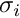 exceeds the baseline (initially determined by the genome)
exceeds the baseline (initially determined by the genome) 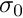 by a factor
by a factor 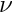 determined by the parameter commondata::sex_steroids_reproduction_threshold:
determined by the parameter commondata::sex_steroids_reproduction_threshold:
![\[ \sigma_{i} > \nu \sigma_{0} . \]](form_55.png)
This check is done by the the_body::is_ready_reproduce() function.
is_reproduce if present, is also set to FALSE and no further processing is then performed.Determine if there are any conspecifics in the perception, if there are no, reproduction is impossible. Return straight away with zero values of gonadal steroid decrements, as in the case of unsuccessful reproduction. The reproduction indicator is_reproduce if present, is also set to FALSE.
Check optional probability of reproduction dummy parameter. If it is absent, use the value calculated from the this_agent agent's perception data calling probability_reproduction() method. This is the upper limit on the reproduction probability provided the actor agent has sufficient motivation and resources.
Then we call stochastic logical function reproduction_success() to determine the actual outcome of reproduction.
If reproduction is successful, the reproductive factor gonadal steroid (hormonal) components reproduce::reprfact_decrement_testosterone` and reproduce::reprfact_decrement_estrogen data component are determined in sex specific manner:
An additional condition is that the level of the gonadal hormones should not fall below the baseline level. Additionally, the cost of reproduction, body mass decrement reproduce::decrement_mass, is calculated and set using the reproduction::reproduction_cost() method.
Also, if is_reproduce optional parameter is provided, set it to TRUE.
If reproduction is not successful, reproduction factor decrements equal to zero are returned. The body mass decrement is equivalent to the reproduction cost of unsuccessful reproduction (reproduction::reproduction_cost_unsuccess()).
Additionally, set is_reproduce to FALSE if it is provided.
Definition at line 7561 of file m_behav.f90.
| subroutine the_behaviour::reproduce_motivations_expect | ( | class(reproduce), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| integer, intent(in), optional | time_step_model, | ||
| real(srp), intent(in), optional | reprod_prob, | ||
| logical, intent(in), optional | non_stochastic, | ||
| real(srp), intent(in), optional | rescale_max_motivation | ||
| ) |
reproduce::motivations_expect() is a subroutine (re)calculating motivations from fake expected perceptions following from reproduce::do_this() => the_behaviour::reproduce_do_this() procedure.
| [in,out] | this | [inout] this the self object. |
| [in] | this_agent | this_agent is the actor agent which does reproduce. |
| [in] | time_step_model | [in] time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
| [in] | reprod_prob | reprod_prob is optional probability of reproduction for the this actor agent, overrides the value calculated from the agent data using the probability_reproduction() function. |
| [in] | non_stochastic | non_stochastic is a logical flag that sets 100% probability of reproduction. This parameter has precedence over the reprod_prob. |
| [in] | rescale_max_motivation | rescale_max_motivation maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
PROBABILITY_REPRODUCTION_BASE_DEF is the expected (subjective) probability of reproduction; set as a parameter.
We assume that the agent assumes 100% probability of reproduction.
reproduction_prob_intrinsic is the probability of reproduction that is intrinsic for the agent at the given conditions, calculated using the probability_reproduction() function.
reprfactor_percept is the value of the reproductive factor that goes as a fake perception value into the neuronal response function. This reproductive factor is determined in a sex specific way:
reprfact_decrement_testosterone in males;reprfact_decrement_estrogen in females.body_mass_percept is the "subjective" value of the energetic cost of reproduction that goes as a fake perception value into the neuronal response function. It is calculated via the reproduction::reproduction_cost() method.
energy_override_perc is the fake perception value for the energy reserves that goes into the neuronal response function.
First, calculate the intrinsic probability of reproduction for this actor agent using the probability_reproduction() method.
Check optional time step parameter. If not provided, use global parameter value from commondata::global_time_step_model_current.
Check if the probability of reproduction is supplied. If the probability of reproduction is supplied as a dummy parameter to this procedure, it will override the intrinsic probability of reproduction for this actor agent that is calculated using the probability_reproduction() method. This may be for example necessary when a subjective motivational expectancy is calculated, it can assume 100% probability and/or weightings of the resulting motivation value(s).
If the probability of reproduction is not supplied, expectancy is based on the intrinsic probability_reproduction() value.
If the non_stochastic dummy parameter is set to TRUE, the probability of reproduction is obtained from the PROBABILITY_REPRODUCTION_BASE_DEF local parameter that is 1.1. In such a case, it guarantees that the agent will always reproduce.
reproduce::do_this() procedure where the reproduction probability is calculated from the true objective values, the subjective expectancies are based by default on 100% expected probability of this agent reproduction.First, we use the do-procedure reproduce::do_this() => the_behaviour::reproduce_do_this() to perform the behaviour desired without changing either the agent or its environment, obtaining the subjective values of the this behaviour components that later feed into the motivation expectancy functions:
reprfact_decrement_testosteronereprfact_decrement_estrogenWe then weight the expected subjective decrements of the reproductive factor components of he_neurobio::reproduce class, testosterone or estrogen, that are intrinsically expected for the actor agent by the objective probability of reproduction reproduction_prob_intrinsic (calculated for the current time step using the intrinsic the_neurobio::probability_reproduction() method). The reproductive factor reprfactor_percept that goes into the neuronal response function as a fake perception is based on gonadal steroid (hormonal) components: reprfact_decrement_testosterone and reprfact_decrement_estrogen in a sex specific manner:
reproduction_prob_intrinsic,reproduction_prob_intrinsic.The same is done for the subjective assessment of the body mass cost of reproduction (body_mass_percept): it is weighted by the intrinsic probability of reproduction (reproduction_prob_intrinsic).
At this point, therefore, the fake perception values for the reproductive factor (reprfactor_percept) and body mass (body_mass_percept) are known. Finally, calculate also the fake perception for the energy reserves (energy_override_perc) using the the_body::energy_reserve() procedure.
Second, we calculate motivation values resulting from the behaviour done (reproduce::do_this() => the_behaviour::reproduce_do_this()) at the previous step: what would be the motivation values if the agent doe perform reproduction? Technically, this is done by calling the neuronal response function, percept_components_motiv::motivation_components() method, for each of the motivational states with perception_override_ dummy parameters overriding the default values: perception_override_reprfac and also perception_override_energy.
Real agent perception components are now substituted by the fake values resulting from executing this behaviour (reproduce::do_this() => the_behaviour::reproduce_do_this() method). This is repeated for all the motivations: hunger, passive avoidance, active avoidance etc. These optional override parameters are substituted by the "fake" values:
perception_override_reprfac;perception_override_bodymass.Third, From the perceptual components calculated at the previous step we can obtain the primary and final motivation values by weighed summing.
Here we can use global maximum motivation across all behaviours and perceptual components if it is provided, for rescaling.
Or can rescale using local maximum value for this behaviour only.
Transfer attention weights from the actor agent this_agent to the this behaviour component. So, we will now use the updated modulated attention weights of the agent rather than their default parameter values.
So the primary motivation values are calculated.
Primary motivations are logged in the debug mode.
There is no modulation at this stage, so the final motivation values are the same as primary motivations. TODO: Should include developmental or other modulation? If yes, need to separate genetic modulation component from motivation_modulation_genetic into a procedure bound to MOTIVATIONS with this_agent as actor.
Fourth, Calculate the finally expected arousal level for this behaviour. As in the GOS, the overall arousal is the maximum value among all motivation components.
Log also the final expectancy value in the debug mode.
Now as we know the expected arousal, we can choose the behaviour which would minimise this arousal level.
Definition at line 7692 of file m_behav.f90.
| subroutine the_behaviour::reproduce_do_execute | ( | class(reproduce), intent(inout) | this, |
| class(appraisal), intent(inout) | this_agent | ||
| ) |
Execute this behaviour component "reproduce" by the this_agent agent.
| [in,out] | this_agent | [inout] this_agent is the actor agent which reproduces. |
body_mass_after is the updated body mass of the agent excluding the cost of reproduction.
First, check if there are any conspecifics in the perception object of the agent and this agent is not dead. It should normally the case. If not, may point to a bug.
Calculate the updated body mass of the agent after reproduction body_mass_after. It is obtained by subtracting the cost of reproduction from the current body mass of the agent. The cost of reproduction is calculated using the function reproduction::reproduction_cost() (=> the_body::reproduction_cost_energy()). Therefore it does not necessarily coincide with the subjective cost of reproduction that is kept in the the_behaviour::reproduce class.
Additionally, check if the energy reserves of the agent and the body mass are enough for reproduction. That is, if the agent survives following the reproduction and does not get starved to death. The check is done using the the_body::is_starved() function in the named if block CHECK_STARVED_AFTER.
reproduction_unsuccessful_cost_subtract() procedure is called to subtract some small cost if unsuccessful reproduction.First, we use the intent-in do-procedure reproduce::do_this() => the_behaviour::reproduce_do_this() to perform the behaviour desired and get the expectations of fake perceptions for GOS:
At this stage, the state of the agent is not changed. Only the state of this behaviour changes, and it will be later passed to modify the agent. The do_this procedure also returns the stochastic status of the reproduction event is_reproduce is TRUE if the reproduction event was successful.
Also log the fake perceptions along with the agent's sex if running in the DEBUG mode.
Second, change the agent's state as a consequence of reproduction. Check if reproduction event was stochastically successful. If the reproduction event was not successful (is_reproduce is FALSE), the reproduction_unsuccessful_cost_subtract() procedure is called to subtract some small cost of unsuccessful reproduction.
Following this, exit and return back from this procedure.
From now on it is assumed that the reproduction event was stochastically successful. (A) Update the number of successful reproductions and the number of offspring that result from this reproduction, for this agent, by the default number (=1) calling reproduction::reproductions_increment().
(B) Decrease the sex steroids level following the reproduction. This is different in males and females: testosterone is decreased in males and estrogen, in females. An additional condition is that the level of gonadal steroids could not fall to less than the baseline.
(C) Decrement the body mass as a consequence of reproduction. This body mass decrement constitutes the energetic cost of reproduction. The updated body mass (after subtraction of the cost) has already been calculated as body_mass_after.
Additionally, also call the the_body::condition::set_length() method to update the body length history stack. However, the value_set parameter here is just the current value. This fake re-setting of the body length is done to keep both mass and length synchronised in their history stack arrays (there is no procedure for only updating history).
After resetting the body mass, update energy reserves of the agent, that depend on both the length and the mass.
(D). Check if the agent is starved to death. If yes, the agent can die without going any further.
Reproduction of the agent does not affect the environmental objects. TODO: add method to do actual reproduction crossover mate choice and produce eggs
Definition at line 8069 of file m_behav.f90.
| subroutine the_behaviour::walk_random_do_this | ( | class(walk_random), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| real(srp), intent(in), optional | distance, | ||
| real(srp), intent(in), optional | distance_cv, | ||
| integer, intent(in), optional | predict_window_pred, | ||
| integer, intent(in), optional | predict_window_food, | ||
| integer, intent(in), optional | time_step_model | ||
| ) |
The "do" procedure component of the behaviour element performs the behaviour without affecting the actor agent (the_agent) and the world (here food_item_eaten) which have intent(in), so it only can change the internal representation of the behaviour (the type to which this procedure is bound to, here WALK_RANDOM).
| [in] | this_agent | this_agent is the actor agent which eats the food item. |
| [in] | distance | distance is an optional walk distance. If stochastic Gaussian walk is set, this value defines the average distance. |
| [in] | distance_cv | distance_cv is an optional coefficient of variation for the random walk distance. If absent, non-stochastic walk step size is used. |
| [in] | predict_window_pred | predict_window_pred the size of the prediction window, i.e. how many steps back in memory are used to calculate the predicted general predation risk. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | predict_window_food | predict_window_food the size of the prediction window, i.e. how many steps back in memory are used to calculate the predicted food gain. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | time_step_model | time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
Check optional time step parameter. If unset, use global commondata::global_time_step_model_current.
Check optional parameter for the general predation risk perception memory window. If the predict_window_pred dummy parameter is not provided, its default value is the proportion of the whole perceptual memory window defined by commondata::history_perception_window_pred. Thus, only the latest part of the memory is used for the prediction of the future predation risk.
Check optional parameter for the food perception memory window. If the predict_window_food dummy parameter is not provided, its default value is the proportion of the whole perceptual memory window defined by commondata::history_perception_window_food. Thus, only the latest part of the memory is used for the prediction of the future food gain.
The normal locomotion distance is fixed to the fraction of the agent current body length set by the parameter commondata::walk_random_distance_default_factor. This is a baseline value that can serve as the mean in case of stochastic walks (the_environment::spatial_moving::rwalk()) or as the actual value in case of deterministic walks.
The walk distance 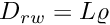 where
where  is the agent's body length and is the parameter factor commondata::walk_random_distance_default_factor.
is the agent's body length and is the parameter factor commondata::walk_random_distance_default_factor.
However, if the walk distance is provided as an optional parameter distance to this procedure, this provided value is used as the baseline distance instead. This allows to easily implement several types of walks, e.g. "long" (migration-like) and short (local).
This baseline distance value  is saved into the
is saved into the this behaviour data component %distance.
distance_cv optional dummy parameter is set to a non-zero value (> commondata::tolerance_high_def_srp), the the walk distance is stochastic with the mean equal to the above baseline value and the coefficient of variation set by the %distance_cv data component of the this walk object, that is in turn equal to the distance_cv parameter.The %distance is then reset to a Gaussian value, creating an error/uncertainty in the expectancy.
distance_cv parameter is absent or is explicitly set to zero, the walk distance is deterministic with the value equal to the baseline. Also, the %distance_c data component is 0.0 for non-stochastic distances.This allows to implement uncertainty in the walk distance depending on different factors, such as the arousal or hormone level.
The expected cost of swimming in the random walk depends on the walk distance and is calculated using the the_body::condition::cost_swim() assuming laminar flow (laminar flow is due to normal relatively slow swimming pattern).
Food item perception expected after a random walk is calculated using the the_behaviour::hope() function mechanism.
First, average number of food items in the "older" and "newer" parts of the memory is calculated using the the_neurobio::memory_perceptual::get_food_mean_n_split() procedure. (Note that the split_val parameter to this procedure is not provided so the default 1/2 split is used.)
Second, the expected number of food items following the walk (%expected_food_dir) is calculated based on the the_behaviour::hope() function mechanism. Here, the baseline value is the current number of food items in the food perception object of the actor agent, and the historical ratio is calculated as the mean number of food items in the "older" to "newer" memory parts:
The grid arrays for the hope function are defined by the obtained from commondata::walk_random_food_hope_abscissa and commondata::walk_random_food_hope_ordinate parameter arrays.
The expected food gain is calculated differently depending on the mean distance of the random walk.
For relatively short walks, the expected food gain is based on the currently available value.
The expected food gain is equal to the average mass of the food item in the latest predict_window_food_here steps of the memory stack, weighted by the average number of food items in the same width latest memory if this number is less than 1 or 1 (i.e. unweighted) if their number is higher.
where  is the average mass of the food items and
is the average mass of the food items and 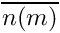 is the average number of food items in the
is the average number of food items in the  latest steps of the perceptual memory stack.
latest steps of the perceptual memory stack.
The averages are calculated with the_neurobio::memory_perceptual::get_food_mean_size() and the_neurobio::memory_perceptual::get_food_mean_n(). The average mass of the food items is calculated from their average size using the the_environment::size2mass_food() function.
Thus, if the agent had previously some relatively poor perceptual history of encountering food items, so that the average number of food items is fractional < 1 (e.g. average number 0.5, meaning that it has seen a single food item approximately every other time step), the expected food is weighted by this fraction (0.5). If, on the other hand, the agent had several food items at each time step previously, the average food item size is unweighted (weight=1.0). This conditional weighting reflects the fact that it is not possible to eat more than one food item at a time in this model version.
This expected food gain is then weighted by the subjective probability of food item capture that is calculated based on the memory the_neurobio::perception::food_probability_capture_subjective().
For relatively long walks, the expected food gain is based on the the_behaviour::hope() function.
First, average size of food items in the "older" and "newer" parts of the memory is calculated using the the_neurobio::memory_perceptual::get_food_mean_size_split() procedure. (Note that the split_val parameter to this procedure is not provided so the default 1/2 split is used.)
Second, the values of the "old" and "new" food gain used to calculate the expectations are obtained by weighting the respective average mass of the food item by the average number of food items if this number is less than 1 or 1 (i.e. unweighted) if their average number is higher.
where is the average mass of the food items and is the average number of food items in the "older" half of the perceptual memory stack and is the average mass of the food items and is the average number of food items in the "newer" half of the memory stack.
Thus, if the agent had some relatively poor perceptual history of encountering food items, so that the average number of food items is fractional < 1 (e.g. average number 0.5, meaning that it has seen a single food item approximately every other time step), the food gain is weighted by this fraction (0.5). If, on the other hand, the agent had more than one food items at each time step previously, the average food item size is unweighted (weight=1.0). This conditional weighting reflects the fact that it is not possible to eat more than one food item at a time in this model version.
The next step is to calculate the baseline food gain , against which the expectancy based on the the_behaviour::hope() function is evaluated. This baseline value is obtained by weighting the average mass of the food items in the whole memory stack by their average number provided this number is n<1 as above:
This baseline food gain is then weighted by the subjective probability of food item capture that is calculated based on values from the the memory the_neurobio::perception::food_probability_capture_subjective().
Finally, the the_behaviour::hope() function is called with the above estimates for the baseline food gain, its "older" and "newer" values. The zero hope ratio and the maximum hope parameters are obtained from commondata::migrate_food_gain_ratio_zero_hope and commondata::migrate_food_gain_maximum_hope parameter constants.
The expected risk of predation (as the food gain above) is calculated differently for relatively short and long walks. The walk is considered short if the distance does not exceed commondata::walk_random_pred_risk_hope_agentl units of the agent body lengths and long otherwise.
First, the current level of the direct risk of predation is calculated using the_neurobio::perception::risk_pred() based on the perception of the this_agent agent assuming the agent is not freezing (because it is going to move a random walk).
Second, calculate the current value of the general predation risk using the the_neurobio::predation_risk_backend() procedure. The size of this limited memory window is set by the predict_window_pred dummy parameter.
In short walks, the expected values are just equal to the above current direct extimates.
On the other hand, for long walks, the expected values of the risks are based on the the_behaviour::hope() function mechanism.
Definition at line 8267 of file m_behav.f90.
| subroutine the_behaviour::walk_random_motivations_expect | ( | class(walk_random), intent(inout) | this, |
| class(appraisal), intent(in) | this_agent, | ||
| real(srp), intent(in), optional | distance, | ||
| real(srp), intent(in), optional | distance_cv, | ||
| integer, intent(in), optional | predict_window_pred, | ||
| integer, intent(in), optional | predict_window_food, | ||
| integer, intent(in), optional | time_step_model, | ||
| real(srp), intent(in), optional | rescale_max_motivation | ||
| ) |
the_behaviour::walk_random::expectancies_calculate() (re)calculates motivations from fake expected perceptions following from the procedure walk_random::do_this() => the_behaviour::walk_random_do_this().
| [in] | this_agent | this_agent is the actor agent which does random walk. |
| [in] | distance | distance is an optional walk distance. If stochastic Gaussian walk is set, this value defines the average distance. |
| [in] | distance_cv | distance_cv is an optional coefficient of variation for the random walk distance. If absent, non-stochastic walk step size is used. |
| [in] | predict_window_pred | predict_window_pred the size of the prediction window, i.e. how many steps back in memory are used to calculate the predicted general predation risk. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | predict_window_food | predict_window_food the size of the prediction window, i.e. how many steps back in memory are used to calculate the predicted food gain. This parameter is limited by the maximum commondata::history_size_perception value of the perception memory history size. |
| [in] | time_step_model | [in] time_step_model optional time step of the model, overrides the value calculated from the spatial data. |
| [in] | rescale_max_motivation | rescale_max_motivation optional maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
The probability of capture of the expected food object.
Expected food gain that is fitting into the stomach of the agent.
perception_override_pred_dir is the expected direct predation risk.
Check optional distance of walk. If it is absent, defined as commondata::walk_random_distance_default_factor times of the agent body length.
Check optional time step parameter. If not provided, use global parameter value from commondata::global_time_step_model_current.
Check optional parameter for the general predation risk perception memory window. If the predict_window_pred dummy parameter is not provided, its default value is the proportion of the whole perceptual memory window defined by commondata::history_perception_window_pred. Thus, only the latest part of the memory is used for the prediction of the future predation risk.
Check optional parameter for the food perception memory window. If the predict_window_food dummy parameter is not provided, its default value is the proportion of the whole perceptual memory window defined by commondata::history_perception_window_food. Thus, only the latest part of the memory is used for the prediction of the future food gain.
As the first step, we use the do-procedure walk_random::do_this() => the_behaviour::walk_random_do_this() to perform the behaviour desired without changing either the agent or its environment, obtaining the subjective values of the this behaviour components that later feed into the motivation expectancy functions:
perception_override_food_dirperception_override_pred_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyThe expected perception of the number of food items that the agent is going to see following the walk is calculated in the do_this procedure. Here it is obtained from the %expected_food_dir data component of the class.
First, create a fake food item with the spatial position identical to that of the agent. The position is used only to calculate the illumination and therefore visual range. The cost(s) are calculated providing explicit separate distance parameter, so the zero distance from the agent is inconsequential. The size of the food item is obtained from the expected food gain by the reverse calculation function the_environment::mass2size_food(). Standard make method for the food item class is used.
Second, calculate the probability of capture of this expected food item. The probability of capture of the fake food item is calculated using the the_environment::food_item::capture_probability() backend assuming the distance to the food item is equal to the average distance of all food items in the current perception object. However, if the agent does not see any food items currently, the distance to the fake food item is assumed to be equal to the visibility range weighted by the (fractional) commondata::walk_random_dist_expect_food_uncertain_fact parameter. Thus, the expected raw food gain (in the do-function) is based on the past memory whereas the probability of capture is based on the latest perception experience.
Third, the expected food gain corrected for fitting into the agent's current stomach and capture cost is obtained by the_body::condition::food_fitting(). It is then weighted by the expected capture probability. Note that the probability of capture (weighting factor) is calculated based on the current perception (see above), but the travel cost is based on the actual expected %distance.
Stomach content: the perception override value for the stomach content is obtained incrementing the current stomach contents by the nonzero expected food gain, adjusting also for the digestion decrement (the_body::stomach_emptify_backend()).
Body mass: the body mass perception override is obtained by incrementing (or decrementing if the expected food gain is negative) the current body mass by the expected food gain and also subtracting the cost of living component.
Energy: The fake perception values for the energy reserves (energy_override_perc) using the the_body::energy_reserve() procedure.
Predation risk: finally, fake perceptions of predation risk are obtained from the values calculated in the do procedure: the_behaviour::walk_random::expected_pred_dir_risk and the_behaviour::walk_random::expected_predation_risk.
The next step is to calculate the motivational expectancies using the fake perceptions to override the default (actual agent's) values. At this stage, first, calculate motivation values resulting from the behaviour done (walk_random::do_this() ) at the previous steps: what would be the motivation values if the agent does perform WALK_RANDOM? Technically, this is done by calling the neuronal response function, percept_components_motiv::motivation_components() method, for each of the motivational states with perception_override_ dummy parameters overriding the default values. Here is the list of the fake overriding perceptions for the WALK_RANDOM behaviour:
perception_override_food_dirperception_override_pred_dirperception_override_predatorperception_override_stomachperception_override_bodymassperception_override_energyReal agent perception components are now substituted by the fake values resulting from executing this behaviour (reproduce::do_this() => the_behaviour::reproduce_do_this() method). This is repeated for all the motivations: hunger, passive avoidance, active avoidance etc. These optional override parameters are substituted by the "fake" values.
Next, from the perceptual components calculated at the previous step we can obtain the primary and final motivation values by weighed summing.
Here we can use global maximum motivation across all behaviours and perceptual components if it is provided, for rescaling.
Or can rescale using local maximum value for this behaviour only.
Transfer attention weights from the actor agent this_agent to the this behaviour component. So, we will now use the updated modulated attention weights of the agent rather than their default parameter values.
So the primary motivation values are calculated.
Primary motivations are logged in the debug mode.
There is no modulation at this stage, so the final motivation values are the same as primary motivations.
Finally, calculate the finally expected arousal level for this behaviour. As in the GOS, the overall arousal is the maximum value among all motivation components.
Log also the final expectancy value in the debug mode.
Now as we know the expected arousal, we can choose the behaviour which would minimise this arousal level.
Definition at line 8731 of file m_behav.f90.
| subroutine the_behaviour::walk_random_do_execute | ( | class(walk_random), intent(inout) | this, |
| class(appraisal), intent(inout) | this_agent, | ||
| real(srp), intent(in), optional | step_dist, | ||
| real(srp), intent(in), optional | step_cv, | ||
| class(environment), intent(in), optional | environment_limits | ||
| ) |
Execute this behaviour component "random walk" by this_agent agent.
| [in,out] | this_agent | [in] this_agent is the actor agent which goes down. |
| [in] | step_dist | step_dist optional fixed distance of the walk. In case the coefficient of variation (next optional parameter) is provided, the walk distance is stochastic with the later coefficient of variation. |
| [in] | step_cv | step_cv Optional coefficient of variation for the walk step, if not provided, the step CV set by the parameter commondata::walk_random_distance_stochastic_cv. |
| [in] | environment_limits | environment_limits Limits of the environment area available for the random walk. The moving object cannot get beyond this limit. If this parameter is not provided, the environmental limits are obtained automatically from the global array the_environment::global_habitats_available. |
Check if the optional coefficient of variation for the step size. If the parameter is not provided, the CV is set from the parameter commondata::walk_random_distance_stochastic_cv.
First, we use the intent-in do-procedure the_behaviour::walk_random::do_this() to perform the behaviour desired. However, Expectancies for food gain and predator risk that are not used at this stage.
The agent does the random walk with the step size this%distance. Therefore, it is now possible to change the state of the agent.
Random walk is done in the "2.5D" mode, i.e. with separate parameters for the horizontal distance (and CV) and vertical depth distance (and its CV). This is done to avoid potentially a too large vertical displacement of the agent (vertical migration involves separate behaviours). Thus, the vertical shift distance should normally be smaller than the horizontal shift. The difference between the main horizontal and smaller vertical shifts is defined by the parameter commondata::walk_random_vertical_shift_ratio. Note that the coefficient of variation for the vertical walk component is set separately using the ratio commondata::walk_random_vertical_shift_cv_ratio.
The agent performs the random walk using the main the_environment::spatial_moving::rwalk() procedure. If the limiting environment is known (environment_limits optional parameter), the rwalk call also includes it. If environmental limits are not provided as a dummy parameter, they are obtained automatically from the global array the_environment::global_habitats_available.
Additionally, also call the the_body::condition::set_length() method to update the body length history stack. However, the value_set parameter here is just the current value. This fake re-setting of the body length is done to keep both mass and length synchronised in their history stack arrays (there is no procedure for only updating history).
Finally, check if the agent is starved to death. If yes, the agent can die without going any further.
Random walk does not affect the environmental objects.
Definition at line 9189 of file m_behav.f90.
|
private |
Initialise the behaviour components of the agent, the the_behaviour::behaviour class.
Initialise the label for the currently executed behaviour to an easily discernible value (e.g. by gre).
Initialise the execution status of each of the behaviour units that compose this class to FALSE (these behavioural units are not executing).
Cleanup the history stack of behaviour labels the_behaviour::behaviour::history_behave.
Initialise anchor behav_debug_indicators "debugging indicators" for the_behaviour::behaviour class.
Definition at line 9315 of file m_behav.f90.
| elemental subroutine the_behaviour::behaviour_whole_agent_deactivate | ( | class(behaviour), intent(inout) | this | ) |
Deactivate all behaviour units that compose the behaviour repertoire of the agent.
Definition at line 9342 of file m_behav.f90.
| elemental character(len=label_length) function the_behaviour::behaviour_get_behaviour_label_executing | ( | class(behaviour), intent(in) | this | ) |
Obtain the label of the currently executing behaviour for the this agent.
Definition at line 9361 of file m_behav.f90.
| integer function the_behaviour::behaviour_select_conspecific | ( | class(behaviour), intent(inout) | this, |
| real(srp), intent(in), optional | rescale_max_motivation | ||
| ) |
Select the optimal conspecific among (possibly) several ones that are available in the perception object of the agent.
| [in] | rescale_max_motivation | rescale_max_motivation maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
expected_gos_consp is an array of motivational GOS expectancies from each of the food items within the perception object.
First, check if the agent has any conspecific(s) within its perception objects using perception::has_consp() method. Return zero straight away if no conspecifics are seen. Therefore, from now on it is assumed that the agent has at least one conspecific in its perception object.
The local variable n_seen_percep is the total number of conspecifics found in the perception object.
If there is only one conspecific, get its number (1) and exit. There is no choice if only a single conspecific is here.
Check if the maximum motivation value for rescale is provided as a parameter.
If provided, use global maximum motivation across all behaviours and perceptual components for rescaling.
If not provided, rescale using local maximum motivation value for this agent.
Calculate GOS expectancies from approaching each of the conspecifics in the perception object. This is implemented in the CONSP_EXPECT loop.
approach_conspec::init() method initialises the attention weights.expected_gos_consp.Once we calculated GOS motivational expectancies for all the food items, we can determine which of the food items results in the minimum arousal.
Definition at line 9373 of file m_behav.f90.
| integer function the_behaviour::behaviour_select_conspecific_nearest | ( | class(behaviour), intent(in) | this | ) |
Select the nearest conspecific among (possibly) several ones that are available in the perception object. Note that conspecifics are sorted by distance within the perception object. Thus, this procedure just selects the first conspecific.
Definition at line 9487 of file m_behav.f90.
| integer function the_behaviour::behaviour_select_food_item | ( | class(behaviour), intent(inout) | this, |
| real(srp), intent(in), optional | rescale_max_motivation | ||
| ) |
Select the optimal food item among (possibly) several ones that are available in the perception object of the agent.
Choosing the optimal food item to catch may be a non-trivial task and different decision rules could be implemented for this.
| [in] | rescale_max_motivation | rescale_max_motivation maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
expected_gos_fitem is an array of motivational GOS expectancies from each of the food items within the perception object.
First, check if the agent has any food item(s) within its perception objects using perception::has_food() method. Return zero straight away if no food seen. Therefore, from now on it is assumed that the agent has at least one food item in its perception object.
The local variable n_seen_percep is the total number of food items found in the perception object.
If there is only one food item, get its number (1) and exit.
Check if the maximum motivation value for rescale is provided as a parameter.
If provided, use global maximum motivation across all behaviours and perceptual components for rescaling.
If not provided, rescale using local maximum motivation value for this agent.
Calculate GOS expectancies from each of the food items in the perception object. This is implemented in the ITEMS_EXPECT loop.
eat_food::init() method initialises the attention weights.eat_food::expectancies_calculate() does the job.expected_gos_fitem.Once we calculated GOS motivational expectancies for all the food items, we can determine which of the food items results in the minimum arousal.
Definition at line 9507 of file m_behav.f90.
| integer function the_behaviour::behaviour_select_food_item_nearest | ( | class(behaviour), intent(in) | this | ) |
Select the nearest food item among (possibly) several ones that are available in the perception object. This is a specific and most simplistic version of the behaviour_select_food_item function: select the nearest food item available in the agent's perception object. Because the food items are sorted within the perception object just select the first item.
Definition at line 9675 of file m_behav.f90.
| subroutine the_behaviour::behaviour_do_eat_food_item | ( | class(behaviour), intent(inout) | this, |
| integer, intent(in), optional | number_in_seen, | ||
| class(food_resource), intent(inout) | food_resource_real | ||
| ) |
Eat a specific food item that are found in the perception object.
| [in] | number_in_seen | The index of the first food item (if there are any food items) within the perception object of the agent. If not set, default is the first (nearest) food item in the perception object. |
| [in,out] | food_resource_real | [inout] food_resource_real The food resource the agent is eating the food item in. Note that it could be a joined food resource composed with the_environment::join() procedure for assembling several habitats into the the_environment::global_habitats_available array or resources collapsed using the the_environment::food_resource::join() method. |
First, check if the agent has any food items in its perception object using the perception::has_food() method. Return straight away if no food perceived.
If there are no food items in the perception object or nothing is chosen, exit without any further processing. Normally this should not occur as the perception::has_food() check method guarantees that there are some food items in the perception object.
If this check is passed set the id of the food perception object.
Finally, init the behaviour object eat before "execute". Calls the eat_food::init() method.
Set the currently executed behaviour label. It is from the the_behaviour::behaviour_base::label data component of the base class.
Set the execution status for all behaviours to FALSE and then for this specific behaviour to TRUE. Only one behaviour unit can be executed at a time.
Do eat the food item chosen using the execute method of the EAT_FOOD class: eat_food::execute().
Update (add to stack) the agent's history of behaviours the_behaviour::behaviour::history_behave: string labels of the behaviours are are saved.
Update (increment) the agent's debugging indicators from indicators:
individual count of successful food items %n_eaten_indicator.
Shift the position of the agent to the position of the food item eaten. That is, the agent itself moves to the spatial position that has been occupied by the food item that has just been consumed.
Definition at line 9692 of file m_behav.f90.
| subroutine the_behaviour::behaviour_do_reproduce | ( | class(behaviour), intent(inout) | this | ) |
Reproduce based on the this agent's current state.
First, check if there are any conspecifics in the perception object. Return straight away if no conspecifics seen. No cost of reproduction is subtracted in such a case.
Then, Init the behaviour (reproduce::init() => the_behaviour::reproduce_init_zero) before "execute".
Set the currently executed behaviour label. It is from the the_behaviour::behaviour_base::label data component of the base class.
Set the execution status for all behaviours to FALSE and then for this specific behaviour to TRUE. Only one behaviour unit can be executed at a time.
Finally, do the reproduction using the reproduce::execute() => the_behaviour::reproduce_do_execute() method from the the_behaviour::reproduce class.
Update (add to stack) the agent's history of behaviours the_behaviour::behaviour::history_behave: string labels of the behaviours are are saved.
Finally, update the positional history stack the_environment::spatial_moving::history: the current spatial position of the agent is re-saved in the history stack using the_environment::spatial_moving::repeat_position().
Definition at line 9784 of file m_behav.f90.
| subroutine the_behaviour::behaviour_do_walk | ( | class(behaviour), intent(inout) | this, |
| real(srp), intent(in), optional | distance, | ||
| real(srp), intent(in), optional | distance_cv | ||
| ) |
Perform a random Gaussian walk to a specific average distance with certain variance (set by the CV).
| [in] | distance | distance is an optional walk distance. If stochastic Gaussian walk is set, this value defines the average distance. |
| [in] | distance_cv | distance_cv is an optional coefficient of variation for the random walk distance. If absent, non-stochastic walk step size is used. |
Then check if the Coefficient of Variation of the distance parameter is also provided. If no, the default If the distance_cv optional dummy parameter is set to the value defined by the commondata::walk_random_distance_stochastic_cv parameter.
Set the currently executed behaviour label. It is from the the_behaviour::behaviour_base::label data component of the base class.
Set the execution status for all behaviours to FALSE and then for this specific behaviour to TRUE. Only one behaviour unit can be executed at a time.
execute method for this behaviour: the_behaviour::walk_random::execute().Update (add to stack) the agent's history of behaviours the_behaviour::behaviour::history_behave: string labels of the behaviours are are saved.
Definition at line 9831 of file m_behav.f90.
| subroutine the_behaviour::behaviour_do_freeze | ( | class(behaviour), intent(inout) | this | ) |
Perform (execute) the the_behaviour::freeze behaviour.
This behaviour has no parameters (e.g. target) and is rather trivial to execute:
Set the currently executed behaviour label. It is from the the_behaviour::behaviour_base::label data component of the base class.
Set the execution status for all behaviours to FALSE and then for this specific behaviour to TRUE. Only one behaviour unit can be executed at a time.
Update (add to stack) the agent's history of behaviours the_behaviour::behaviour::history_behave: string labels of the behaviours are are saved.
Finally, update the positional history stack the_environment::spatial_moving::history: the current spatial position of the agent is re-saved in the history stack using the_environment::spatial_moving::repeat_position() method.
Definition at line 9900 of file m_behav.f90.
| subroutine the_behaviour::behaviour_do_escape_dart | ( | class(behaviour), intent(inout) | this, |
| class(spatial), intent(in), optional | predator_object | ||
| ) |
Perform (execute) the the_behaviour::escape_dart behaviour.
| [in] | predator_object | predator_object optional predator object, if present, it is assumed the actor agent tries to actively escape from this specific predator. |
Set the currently executed behaviour label. It is from the the_behaviour::behaviour_base::label data component of the base class.
Set the execution status for all behaviours to FALSE and then for this specific behaviour to TRUE. Only one behaviour unit can be executed at a time.
Update (add to stack) the agent's history of behaviours the_behaviour::behaviour::history_behave: string labels of the behaviours are are saved.
Definition at line 9942 of file m_behav.f90.
| subroutine the_behaviour::behaviour_do_approach | ( | class(behaviour), intent(inout) | this, |
| class(spatial), intent(in) | target_object, | ||
| logical, intent(in), optional | is_random, | ||
| real(srp), intent(in), optional | target_offset | ||
| ) |
Approach a specific the_environment::spatial class target, i.e. execute the the_behaviour::approach behaviour. The target is either a conspecific from the perception (the_neurobio::conspec_percept_comp class) or any arbitrary the_environment::spatial class object.
| [in] | target_object | target_object is the spatial target object the actor agent is going to approach. |
| [in] | is_random | is_random indicator flag for random correlated walk. If present and is TRUE, the agent approaches to the target_object in form of random correlated walk (see the_environment::spatial_moving::corwalk()), otherwise directly. |
| [in] | target_offset | target_offset is an optional offset for the target, so that the target position of the approaching agent does not coincide with the target object. If absent, a default value set by the commondata::approach_offset_default is used. For the the_behaviour::approach_conspec, the default value is as an average of the agent and target conspecific body lengths. |
is_random: if the parameter is set to TRUE, a random Gaussian walk towards the target object is done, otherwise a direct direct approach towards the target object leaving the target offset distance is performed.Check the type of the target object. Different targets are processed differently for approach.
Update (add to stack) the agent's history of behaviours the_behaviour::behaviour::history_behave: string labels of the behaviours are are saved.
Update (add to stack) the agent's history of behaviours the_behaviour::behaviour::history_behave: string labels of the behaviours are are saved.
Definition at line 9987 of file m_behav.f90.
| subroutine the_behaviour::behaviour_do_migrate | ( | class(behaviour), intent(inout) | this, |
| class(environment), intent(in) | target_env | ||
| ) |
Perform (execute) the the_behaviour::migrate (migration) behaviour.
| [in] | target_env | target_env the target environment the actor agent is going to (e)migrate into. |
Set the currently executed behaviour label. It is from the the_behaviour::behaviour_base::label data component of the base class.
Set the execution status for all behaviours to FALSE and then for this specific behaviour to TRUE. Only one behaviour unit can be executed at a time.
Update (add to stack) the agent's history of behaviours the_behaviour::behaviour::history_behave: string labels of the behaviours are are saved.
Definition at line 10090 of file m_behav.f90.
| logical function the_behaviour::behaviour_try_migrate_random | ( | class(behaviour), intent(inout) | this, |
| class(environment), intent(in) | target_env, | ||
| real(srp), intent(in), optional | max_dist, | ||
| real(srp), intent(in), optional | prob | ||
| ) |
Perform a simplistic random migration. If the agent is within a specific distance to the target environment, it emigrates there with a specific fixed probability.
| [in] | target_env | target_env the target environment the actor agent is going to (e)migrate into. |
| [in] | max_dist | max_dist Optional maximum distance, in units of the agent's body size, towards the target environment when the agent can (probabilistically) emigrate into it. |
| [in] | prob | prob Probability of migration |
distance_target is the distance to the target environment.
prob.The function returns FALSE whenever the agent has not actually migrated into the target environment.
Optional parameters max_dist and prob are checked and the default values are set in case any of them is absent.
max_dist = MAX_DIST_DEFAULT (commondata::migrate_random_max_dist_target)prob = 0.5.First, determine the nearest target point within the target environment and calculate the distance to the target point.
The distance towards the target environment (and the target point in this environment) is defined as the minimum distance towards all segments limiting this environment in the 2D X x Y projection
The target point for the migrating agent within the target environment is then not just the edge of the target environment, but some point penetrating inside to some distance defined by the parameter commondata::migrate_dist_penetrate_offset (in units of the agent's body length). The the_environment::environment::nearest_target() method is used to find the closest point in the target environment and the (smallest) distance towards this environment, these values are adjusted automatically for the offset parameter in the procedure call.
If the distance towards the target environment does not exceed max_dist body lengths of the agent, the agent can move into this target environment, exactly to the target point point_target_env with the probability prob.
is_migrated is set to TRUE. (Otherwise, it is always FALSE.)This only concerns the cases when the agent had migrated into the target environment target_env.
Additionally, also call the the_body::condition::set_length() method to update the body length history stack. However, the value_set parameter here is just the current value. This fake re-setting of the body length is done to keep both mass and length synchronised in their history stack arrays (there is no procedure for only updating history).
Finally, check if the agent is starved to death. If yes, the agent can die without going any further.
Definition at line 10127 of file m_behav.f90.
| subroutine the_behaviour::behaviour_do_go_down | ( | class(behaviour), intent(inout) | this, |
| real(srp), intent(in), optional | depth_walk | ||
| ) |
Perform (execute) the the_behaviour::go_down_depth (go down) behaviour.
| [in] | depth_walk | depth_walk Optional downward walk size, by how deep the agent goes down. |
Set the currently executed behaviour label. It is from the the_behaviour::behaviour_base::label data component of the base class.
Set the execution status for all behaviours to FALSE and then for this specific behaviour to TRUE. Only one behaviour unit can be executed at a time.
depth_walk, otherwise the default step is used that is equal to the commondata::up_down_walk_step_stdlength_factor times of the agent body length.Update (add to stack) the agent's history of behaviours the_behaviour::behaviour::history_behave: string labels of the behaviours are are saved.
Definition at line 10267 of file m_behav.f90.
| subroutine the_behaviour::behaviour_do_go_up | ( | class(behaviour), intent(inout) | this, |
| real(srp), intent(in), optional | depth_walk | ||
| ) |
Perform (execute) the the_behaviour::go_up_depth (go up) behaviour.
| [in] | depth_walk | depth_walk Optional downward walk size, by how deep the agent goes up. |
Set the currently executed behaviour label. It is from the the_behaviour::behaviour_base::label data component of the base class.
Set the execution status for all behaviours to FALSE and then for this specific behaviour to TRUE. Only one behaviour unit can be executed at a time.
depth_walk, otherwise the default step is used that is equal to the commondata::up_down_walk_step_stdlength_factor times of the agent body length.Update (add to stack) the agent's history of behaviours the_behaviour::behaviour::history_behave: string labels of the behaviours are are saved.
Definition at line 10310 of file m_behav.f90.
| elemental subroutine the_behaviour::behaviour_cleanup_history | ( | class(behaviour), intent(inout) | this | ) |
Cleanup the behaviour history stack for the agent. All values are empty.
Definition at line 10354 of file m_behav.f90.
| subroutine the_behaviour::behaviour_select_optimal | ( | class(behaviour), intent(inout) | this, |
| real(srp), intent(in), optional | rescale_max_motivation, | ||
| class(food_resource), intent(inout), optional | food_resource_real | ||
| ) |
Select and execute the optimal behaviour, i.e. the behaviour which minimizes the expected GOS arousal.
| [in,out] | food_resource_real | [inout] food_resource_real The food resource the agent is eating the food item in. Note that it could be a joined food resource composed with the_environment::join() procedure for assembling several habitats into the the_environment::global_habitats_available array or resources collapsed using the the_environment::food_resource::join() method. |
| [in] | rescale_max_motivation | rescale_max_motivation maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
expected_gos_eat is the GOS expectancy value predicted from eating the optimal food item.
expected_gos_all array might not work on all compilers and platforms. If manually allocated, check the exact number of behaviour units.Determine optional parameter rescale_max_motivation. If it is absent from the parameter list, the value is calculated from the current perception using the the_neurobio::motivation::max_perception() method.
First, the expectancies of the GOS arousal from each of the available behaviour units are calculated.
Eat food (the_behaviour::eat_food) calling eat_food_select().
After the GOS arousal values for all behaviour units are calculated, the agent can determine the minimum value and what is the associated behaviour unit that minimises the GOS arousal.
First, an array containing all GOS arousal values for all of the above behaviour units is constructed expected_gos_all.
allocate command here as all fairly modern Fortran compilers support automatic allocation of arrays on intrinsic assignment. This feature should work by default in GNU gfortran v.4.6 and Intel ifort v.17.0.1. Automatic allocation allows to avoid a possible bug when the number of array elements in the allocate statement is not updated when the expected_gos_ components of the array are added or removed.Automatic array allocation is checked. If the ` expected_gos_all array turns out not allocated, a critical error is signalled in the logger.
In the DEBUG mode, the array of the GOS arousal levels is logged.
Second, each of the behaviours is checked for being the minimum value. If true, this behaviour is executed using the do_ method of the the_behaviour::behaviour class.
Additionally, for each behaviour unit, an additional check is performed to make sure the conditions for the behaviour are satisfied. If the conditions are not satisfied, a default Gausssian random walk the_behaviour::behaviour::do_walk() is done.
The correctness conditions for each of the behaviour units are:
the_behaviour::reproduce: the agent must be mature (the_body::reproduction::is_ready_reproduce() is TRUE) and have conspecifics in perception (the_neurobio::perception::has_consp() is TRUE).
walk_distance_selected must be nonzero, i.e. exceed the tolerance value commondata::tolerance_high_def_srp.habitat_selected_n must correspond to a valid habitat in the global array the_environment::global_habitats_available.go_down_distance_selected must be nonzero, i.e. exceed the tolerance value commondata::tolerance_high_def_srp.go_up_distance_selected must be nonzero, i.e. exceed the tolerance value commondata::tolerance_high_def_srp.The control is passed back out of this procedure on execution of the optimal behaviour. However, if no behaviour was selected up to this point, the agent just does a default Gaussian walk. However, this situation is very suspicious and can point to a bug. Therefore, such situation is logged with the ERROR tag.
Definition at line 10367 of file m_behav.f90.
| subroutine the_behaviour::behaviour_select_fixed_from_gos | ( | class(behaviour), intent(inout) | this, |
| real(srp), intent(in), optional | rescale_max_motivation, | ||
| class(food_resource), intent(inout), optional | food_resource_real | ||
| ) |
Select and execute behaviour based on the current global organismic state. This procedure is significantly different from the_behaviour::behaviour_select_optimal() in that the behaviour that is executed is not based on optimisation of the expected GOS. Rather, the current GOS fully determines which behaviour unit is executed. Such a rigid link necessarily limits the range of behaviours that could be executed.
| [in,out] | food_resource_real | [inout] food_resource_real The food resource the agent is eating the food item in. Note that it could be a joined food resource composed with the_environment::join() procedure for assembling several habitats into the the_environment::global_habitats_available array or resources collapsed using the the_environment::food_resource::join() method. |
| [in] | rescale_max_motivation | rescale_max_motivation maximum motivation value for rescaling all motivational components for comparison across all motivation and perceptual components and behaviour units. |
do_behave, the nearest food item is selected.predator_selected_n - the predator object within the perception, that is considered the most subjectively dangerous for the agent. (This is actually the number of the predator within the perception object.) Note that in this version of do_behave, the nearest predator is selected.
Determine optional parameter rescale_max_motivation. If it is absent from the parameter list, the value is calculated from the current perception using the the_neurobio::motivation::max_perception() method.
Random migration is implemented in the TRY_MIGRATE block.
ith habitat does not coincide with the current agent's habitat (i.e. the agent cannot emigrate to the currently occupied habitat), the agent tries to perform random migration the_behaviour::behaviour::migrate_random().Note that the loop is terminated (exit) if migration into the i-th habitat was successful. The agent can perform only a single behaviour (migration across habitats) per a single time step.
If the migration was successful, no further behaviour is executed, it is assumed that the agent has executed the_behaviour::migrate behaviour unit.
Fixed behaviour selection is implemented in the SELECT_BEHAVconstruct. Each of the GOS is rigidly associated with a specific behaviour pattern.
at least one food item is present within the perception object, calls the the_behaviour::eat_food() method for the nearest food item.
Definition at line 11236 of file m_behav.f90.
|
private |
Initialise neuro-biological architecture.
Initialise neurobiological components of the agent.
Definition at line 11381 of file m_behav.f90.
|
private |
Definition at line 26 of file m_behav.f90.