This topic describes how to profile an application for function or loop execution time. Using the instrumentation method to profile function or loop execution time provides an easy means of getting a view of where cycles are being spent in your application. The Intel® compiler inserts instrumentation code into your application to collect the time spent in various locations. Such data helps you to identify hotspots that may be candidates for optimization tuning or targeting parallelization.
Different levels of instrumentation are available because of the difference in the overhead associated with the inserted probe points that read the CPU cycle counter. The instrumentation levels, in increasing amount of collected data, are grouped as follows:
- Function level
- Function and loop level
You do not need to profile the entire application but it is recommended that the same level of instrumentation is used for all instrumented files. Compile your application with the command line options described below for all the files that require profile information.
After the instrumented application is run, data files containing a summary of the collected data are created in the working directory. View these data files to identify the time proportions of the different parts of your application.
Compiler Options to Obtain Instrumented Program
Use the following command-line compiler options to instrument your application code to profile execution times for functions/loops. When you compile your application using any one of these options, you get an instrumented program.
| Instrumentation Level | Linux* or OS X* Operating System | Windows* Operating System | Description |
|---|---|---|---|
| Function level | -profile-functions | /Qprofile-functions | Instruments function entry/exit points
only.
|
| Function and loop level | -profile-loops=<arg> | /Qprofile-loops:<arg> | Instruments function and loop entry/exit
points:
|
| Loop body level | -profile-loops-report=[n] | /Qprofile-loops-report:[n] | Controls level of instrumentation for loop
bodies where:
|
Note
Because this instrumentation relies on the CPU time stamp counter for collecting timing information, only single threaded applications should be profiled with these options. Using these options with other compiler options that enable parallel code generation is not supported.
Output Formats Obtained on Running Instrumented Program
After compiling your application using the options, you obtain an instrumented program. Run this instrumented program with a representative set of data to create one or more data files.
The output files are produced by a routine that is registered with the atexit() routine, and are created only when the program exits via a standard exit procedure. Two formats of the output files are created:
- A plain text file using ‘tab’ delimiters, which can be viewed within a text editor or a spreadsheet.
- An XML data file that can be loaded into the data viewer application.
Text Output Format
The text output is written into separate files in the current directory. The filenames are loop_prof_funcs_<timestamp>.dump and loop_prof_loops_<timestamp>.dump for functions and loops respectively. The <timestamp> value is the same for both files to indicate they are from the same instrumentation run.
You can load the text files into a spreadsheet by specifying that the data is delimited with ‘tab’ delimiters.
The function report file contains the following columns:
| Column Heading | Description |
|---|---|
Time (abs) |
Total accumulated cycles spent between function entry and exit. |
Time % |
Percentage of total application time for cycles between function entry and exit. |
Self (abs) |
Accumulated cycles spent between function entry and exit less the cycles spent within calls to other instrumented functions. NoteTime spent in calls to routines or libraries that were not instrumented are included within this cycle count value. |
Self % |
Percentage that self(abs) represents of total application time. |
Call count |
Number of times the function was entered. |
Exit count |
Number of times the function exit instrumentation was invoked. In some instances, such as cases involving exception handling, it may be possible for control to transfer out of a function without the exit instrumentation being seen, resulting in this being different than the call count value. |
Loop ticks (%) |
The percentage of total application time for the self-time cycles of loops within the function. This field is relevant only when you use [Q]profile-loops compiler option. |
Function |
Demangled function name |
File:line |
Source file containing the code for the function, and the line number the function begins on. |
The loop report file contains the following columns:
| Column Heading | Description |
|---|---|
| Time (abs) | Total accumulated cycles spent between loop entry and exit. |
| Time % | Percentage of total application time for cycles between loop entry and exit. |
| Self (abs) | Accumulated cycles spent between loop entry and exit less the cycles spent within calls to other instrumented functions/loops. |
| Self % | Percentage that self(abs) represents of total application time. |
| Loop entries | Number of times the loop was entered. |
| Loop exits | Number of times the loop exit instrumentation was invoked. In some instances, such as cases involving exception handling, it may be possible for control to transfer out of a loop without the exit instrumentation being seen, resulting in this being different than the call count value. |
| Min iteration counts | The smallest iteration count for an invocation of the loop. This field is relevant only when you use instrumentation level = 2, using the [Q]profile-loops-report=2 compiler option. |
| Avg iteration counts | The average iteration count for an invocation of the loop. This field is relevant only when you use instrumentation level = 2, using the [Q]profile-loops-report=2 compiler option. |
| Max iteration counts | The largest iteration count for an invocation of the loop. This field is relevant only when you use instrumentation level = 2, using the [Q]profile-loops-report=2 compiler option. |
| Function | Demangled function name that executed the loop; this may be different from the function that contained the loop source code, if that function was inlined into another function. |
| Function file:line | The name of the source file containing the function that executed the loop, and the line number the function begins on. |
| Loop file:line | The name of the source file containing the loop body, and the line number the loop body begins on. |
XML Output Format
The INTEL_LOOP_PROF_XML_DUMP environment variable is used to control the creation of the XML output format. When INTEL_LOOP_PROF_XML_DUMP = 0, no XML file is created.
The XML output file, named loop_prof_<timestamp>.xml, is written into the current directory. This file is viewed with the data viewer utility. The XML data file contains both the function and loop level data.
Remember, using the environment variable with a value of 0 implies that the data viewer utility is not going to be used since no XML data files are created.
Data Viewer Utility
You must have the Java Runtime Environment, version 1.6 or later installed on your system to use the data viewer utility. The JRE is not included with the Intel® Compiler package.
The Data Viewer displays the data collected for the functions and loops in a sequence of columns that allows for sorting of individual columns. The Data Viewer also provides the ability to filter the function or loops to only display items that meet some threshold amount (total time % or self-time %) of the total application time, or to only show loops that are associated with a particular function.
To launch the Data Viewer utility, or use the following commands from the command line:
On Windows* operating system:
loopprofileviewer[.bat] <datafile>On Linux* and OS X* operating systems:
loopprofileviewer.sh <datafile>or
loopprofileviewer.csh <datafile>The main user interface displays an upper pane, Function
Profile, containing function level data, and a lower pane,
Loop Profile, containing loop level data. If the XML data file
is created using only function level instrumentation, the lower pane is not
displayed. Drag the separator between individual panes to resize them or click
the up/down arrows available on the separator line.
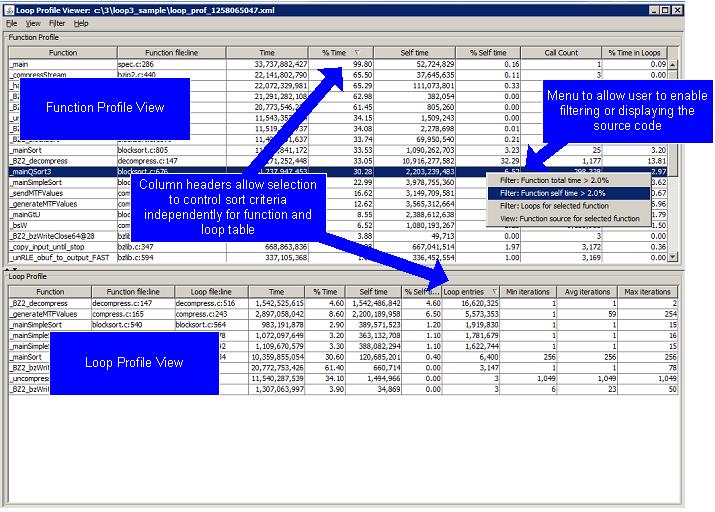
The Function Profile pane and Loop Profile pane contain the set of columns described in the section, Text Output Format. Click on any of these columns to sort the data based on that column.
The Data Viewer utility has two specific menus - the View menu and the Filter menu - in the menu bar besides the generic File and Help menus.
View Menu
The View menu allows you to open a window that shows the source code for the line you have selected in the table (these menus are grayed out if no line is selected). To use the View menu:
- Select a line in the Function Profile pane.
- Go to View > Function source for selected function to see the source code for the selected function.
- Select a line in the Loop Profile pane.
- Go to View > Function source for selected loop to see the source code for the selected function.
- Go to View > Loop source for selected loop to see the source code for the selected loop.
Note
The source code displayed is the current version of the file, in the directory the file was compiled from when the instrumentation compilation was performed.When the cursor is within the Function Profile pane or the Loop Profile pane, right-click on any line to display a popup menu that gives access to these View menu options.
By default, the Data Viewer utility displays the most relevant columns based on the data file loaded. Go to View > Select Columns to display or hide the columns. In the dialog box that opens, columns not available for the currently loaded data file are grayed out.
Filter Menu
The Filter menu allows you to limit the data displayed in the tables to items that meet some criteria. As an example, you can use the Filter menu as follows:
- Go to Filter > Function Profile > “Self time > 1.00%” to list only the functions in the Function Profile pane that represented more than 1.0 % of the application time.
- Go to Filter > Set thresholds to modify the default thresholds used when enabling the filters for total time % or self-time %.
To display only the loops of a particular function, do the following:
- Select a function in the Function column of the Function Profile pane.
- Go to Filter > Loop Profile > Show loops for selected function to display the loops for the selected function.
When the cursor is within the Function Profile pane or the Loop Profile pane, you can right-click any function to display a popup menu that gives access to these Filter menu options.